人工知能分野のトップ国際会議 AAAI2026 現地参加レポート

こんにちは、AIソリューショングループの大沢直史です。普段は生成AIに関する研究開発・調査を行っています。
以下のプレスリリースにもありますように、先日私の論文が人工知能分野の国際学会であるAAAI2026のワークショップに採択されました。
そのため2026年1月20日から27日までシンガポールで開催されていた本会議と併設ワークショップに現地参加をし、AIエージェントやLLMの技術動向を調査とワークショップにおけるポスター発表を行いました。
本記事では、AAAIを通して見えた最新の研究動向や学会の様子、ワークショップに参加して感じたことをお伝えします。

目次
AAAI2026現地レポート
AAAI(The Association for the Advancement of Artificial Intelligence)は人工知能分野の世界トップレベル国際会議であり、歴史のある学会です。他のCS分野の学会は画像処理やデータマイニング、ロボティクスなど主に個別テーマを扱うのに対し、本学会は比較的多岐にわたるAIに関するテーマ全般を扱う学会です。
AAAI2026は今回初めて北米以外のシンガポールで開催され、現地参加登録者は1万人ほどでした。AITCからは大沢と、Know Narratorの開発リードである村本と参加してきました。日本からは直行便があり、時差が1時間しかないため比較的楽に移動できる国だなという印象を受けました。

学会の様子
オープニングセッションはフライトの都合で間に合いませんでしたが、録画とスライドが共有されました。
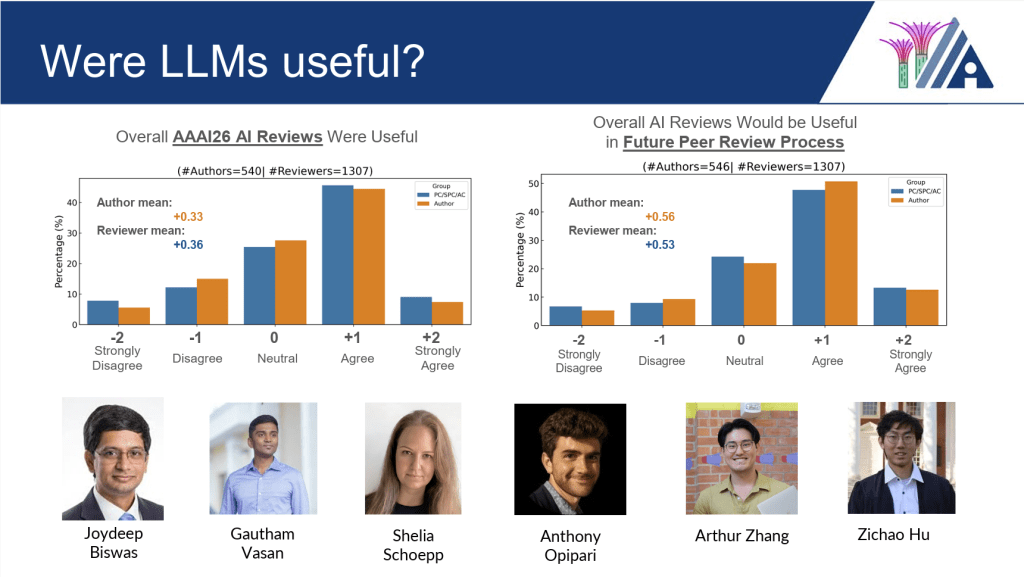
印象的だったのは、LLMを査読プロセスに組み込むパイロットプログラム(AI Review Pilot Program)が実施された点です。Phase1の査読において、人間のレビューに加えて「明示的にラベル付けされたAI生成レビュー」が追加される形式が採用されました。スコア付与や最終判断は人間が担い、AIは追加視点の提供という役割に留められていました。
AIレビューの査読結果について、著者・査読者ともに一定程度有用であったと評価しており、将来的な活用可能性についてはより前向きな意見が示されていました。
ポスターセッションは大きな会場の中にNLP、Roboticsなどトピックごとにポスターがまとめられていました。端が見えないほどの大きな会場で、気になるポスターを見て回るだけであっという間に時間が過ぎていきました。

私が見た発表の中で感じたこととしては、コンテキスト長の増加に伴いLLMに与える情報をどう管理するか、マルチターンになっていく会話をどう管理するかなどLLMの性能向上に伴う研究テーマが増えている印象を受けました。
また複数のクラウドベンダーモデルを簡単に扱えるようになってきていることから、ユースケースにあったLLMモデルを選択する手法やLLM as a Judgeの効果的なLLMモデル選定など、複数のモデルを扱えるようになったからこその課題に対する研究も増えた印象を受けました。
個人的に興味深かった論文を紹介します。
- Don't Start Over: A Cost-Effective Framework for Migrating Personalized Prompts Between LLMs
- 異なるLLM間でユーザーのパーソナライズドプロンプトを効率的に移行する枠組み「PUMA」を提案
- 軽量なアダプタを用いてプロンプトの意味空間を橋渡しし、大規模な再学習なしでモデル間移行を可能
- 実験では、フル再学習と同等以上の性能を、最大50倍の速度向上で達成
- 複数のLLMモデルが利用可能な現状において、モデル間を跨いでタスクパフォーマンスを維持することは重要な課題だと考えており、この研究はドメイン特化のタスクにも応用できるアイデアであると感じました。
- Multi-Turn Intent Classification for LLM-Powered Dialogue System in Production: Balancing Accuracy and Efficiency
- LLMを活用した対話システムにおけるマルチターン(複数往復)意図分類を、本番環境で高精度かつ低コストに実現する方法を提案
- 従来は複数ターンの文脈を考慮すると精度は上がる一方で、アノテーション(ラベル付け)コストが高いという課題があった
- 提案手法「C-LARA」は、RAGとLLMに対して複数の推論パターンで同じ入力を評価させ、その結果が一致しているかで信頼度を判断する仕組みである自己整合性プロセスを組み合わせることで効率よく疑似ラベルを生成し、少ないコストで高品質な学習データを構築
- オフライン評価では既存手法より精度を向上させつつアノテーションコストを約40%削減。さらに実運用でも、問い合わせ解決率や顧客満足度の改善
- これはShopeeの発表で、実際のシステム運用上発生する課題に対応した実務的価値のある研究でした。
- T-Retriever: Tree-based Hierarchical Retrieval Augmented Generation for Textual Graphs
- 既存のGraphRAGは、グラフの構造と意味を同時に扱うのが難しく、階層情報の活用が不十分という課題があった
- 本研究では、この問題を解決するために、グラフをツリー構造へ変換し階層的に検索を行う手法「T-Retriever」を提案している。中核となるのは、構造と意味を同時に最適化する Semantic-Structural Entropy(S²-Entropy) に基づく分割手法であり、意味的にも構造的にも一貫したクラスタを生成
- さらに、各ツリーノードをLLMによって要約し、クエリに応じて適切な粒度でサブグラフを取得するマルチ解像度検索を実現することで、効率的かつ精度の高い情報取得を可能にしている
- 結果として既存手法より高い性能を達成するとともに、LLMのトークン使用量を約84%削減することに成功
本学会での発表内容:Personalization in the Era of Large Foundation Models
Workshop @ AAAI 2026
続いて参加したワークショップについて紹介します。
私が採択されたワークショップは大規模基盤モデルのパーソナライゼーションというテーマを扱うものでした。

キーノートでは、LaMPの論文でこの分野ではとても有名なZamani先生によるLLMにおける代表的なパーソナライゼーション手法の紹介や、金融領域におけるユーザー情報をクラスタリングした推薦システムの実運用についての紹介などが行われていました。
ポスターセッションではあちこちで議論が活発に行われており、私の発表に関しては、パーソナライゼーションを構築したメモリをどう継続的に更新するか?やタスクに応じて差が出るか?など、実際の運用を見据えた質問が複数ありました。メモリはパーソナライゼーション以外にも多くの活用先がありますので、今後も注視していきたいと思います。



シンガポール滞在の様子
AAAIのノベルティの充実ぶりにとても驚きました。
傘やピンバッジなど、普段からAAAIを身に着けることができそうです。

現地で有名なカヤトーストも食べました。
カヤ・ジャムがとてもおいしく、お土産にも買って帰りました。

また学会最終日には夜景を見に行きました。マリーナベイ・サンズから景色を見たり、噴水ショーも見ました。

まとめ
本会議・ワークショップと合わせて約1週間AAAIに参加し、最先端の研究知見や製品開発に活かすことが出来そうなアイデアなど多くの学びがある場でした。またワークショップの現地ワークショップの発表は緊張もありましたが、同様の課題を抱える研究者や企業の方とディスカッションすることができとても有意義な時間となりました。
得られた知見は、日々の業務におけるエージェントの開発や、研究開発、Know Narratorの製品開発にも活かしていく予定です。
今後もAITCは生成AIに関して積極的に製品開発・技術支援をしていきます。
ご相談を希望される方は、お気軽にこちらのお問い合わせフォームからご連絡ください。
執筆
AIソリューショングループ
大沢直史
