Azure AI 音声でオンライン会議でリアルタイムに字幕を画面に表示する

こんにちは、AIソリューショングループの大沢直史です。
最近ではオンライン会議が一般化し、Microsoft TeamsやGoogle Meetなどのツールが普及し、日常的に利用されている方がほとんどではないでしょうか。そしてビジネスの現場では、オンライン会議のみならず、ウェビナー、社内研修、セミナー、さらにはカスタマーサポートなど、オンライン上での「伝える力」がますます重要になっています。しかし、参加者の聞き取り環境はさまざまで、「聞き逃し」や「聞き間違い」による認識のズレが発生しやすいのも現実です。
そこで本記事では、Azure AI 音声とライブ配信や録画を行うためのオープンソースソフトウェアであるOpen Broadcaster Softwareを活用し、リアルタイムに音声を認識し、カメラ映像上に字幕テキスト(キャプション)を表示する方法をご紹介します。これにより、聞き取りづらさや環境音による会話の途切れといった課題を解消し、伝わりやすい会議や配信が実現できます。
※先日OpenAI社から新しい音声モデル「GPT-4o Transcribe」「GPT-4o mini Transcribe」が発表され、Whisperに代わる新しいSpeech-to-textモデルがリリースされました!(記事はこちら)発表記事によると、GPT-4o TranscribeはWhisperモデルに比べ、複数のベンチマークスコアにおいて単語誤り率(WER)のパフォーマンスが向上しているそうです。Azureではまだ使用できませんが、デプロイされ次第音声認識の精度検証を行いたいと思います。
Azure AI 音声
Azure AI 音声とは、Microsoftが提供する音声サービスのAzureリソースです。Azure AI 音声では、音声のテキスト変換(Speech to text)やテキストの音声変換(Text to speech)、音声翻訳(Speech Translation)を中心とし、様々な音声サービスを活用することが可能です。今回はこのサービスを活用し、自分の発する音声をリアルタイムにテキスト化します。
音声のテキスト変換に使用可能なモデルとして、現在Azure Speech to TextとAzure OpenAI ServiceのWhisperが検討できます。しかしながらWhisperはもともとバッチ処理(録音済み音声をまとめて認識する用途)向けに設計されており、今回のテーマとしているリアルタイムキャプショニングのユースケースでは適切ではないと考え、前者のAzure Speech to Textを用いた実装を行うこととしました。

Open Broadcaster Software
続いて、Azure AI 音声によって作成されたテキストを字幕化し、カメラ映像と合成するためのソフトウェアを紹介します。
Open Broadcaster Software(以後、OBS)は、ライブ配信や録画を行うためのオープンソースソフトウェアです。YouTube、Twitch、Facebook Liveなどのプラットフォームに対応しており、無料で利用できます。
また、仮想カメラというOBSの映像を Zoom・Google Meet・Microsoft Teamsなどのビデオ通話アプリ にカメラ映像として出力できる機能があります。今回はOBS内でカメラ映像とキャプションをレイヤーとして重ね、1つの映像として仮想カメラ経由で Teams 会議に使用します。

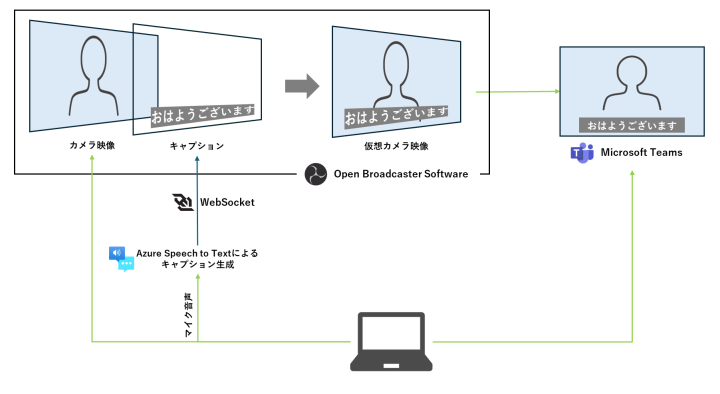
システム構成
本記事のシステム構成を以下に示します。
ポイントはAzure Speech to TextとWebSocketを利用して、HTMLテキストを生成する仕組みです。近年のライブ配信・Web配信の急拡大に伴い、HTMLベースのテロップシステムは多くのサービスが展開されるようになりました。テレビ業界でも配信技術の逆輸入として、特にスポーツ番組を中心に、中継先で作成したテロップをWebSocketを利用して実際の放送映像にレイヤーする構成がとられるようになっています。今回はリッチなテロップではなく最低限のキャプションを表示するのみにとどまるため、スクラッチで実装を行います。
実装
Azure Speech to Textによる音声認識
初めにAzureのSDKを利用したSpeech to Textの処理です。基本的にはAzureのサンプルコードをベースに実装しています。マイクからリアルタイムで音声を取得し、Azureの音声認識サービスを使ってテキストに変換します。主な処理の流れは以下の通りです。
- AzureのSpeech SDKを初期化し、音声認識のための設定を行う。
- マイクから音声を取得し、Azureのクラウドサービスに送信する。
- 音声認識の結果をコールバック関数を使って処理する。
- セマンティックセグメントを有効化し、文脈を考慮した音声認識を行う。
import os
from dotenv import load_dotenv
import azure.cognitiveservices.speech as speechsdk
class AISpeech:
def __init__(self):
load_dotenv() # .env ファイルを読み込む
# Azureの音声認識設定
speech_config = speechsdk.SpeechConfig(
subscription=os.environ.get("SPEECH_KEY"),
region=os.environ.get("SPEECH_REGION"),
)
# セマンティックセグメントを有効化
speech_config.set_property(speechsdk.PropertyId.Speech_SegmentationStrategy, "Semantic")
# 言語を設定
speech_config.speech_recognition_language = "ja-JP"
# 音声認識インスタンスを作成
self.speech_recognizer = speechsdk.SpeechRecognizer(
speech_config=speech_config
)
# 結果を格納するための変数
self.recognized_text = ""
self.recognizing_text = ""
# コールバック関数を登録
self.speech_recognizer.recognized.connect(self.recognized_callback)
self.speech_recognizer.recognizing.connect(self.recognizing_callback)
# 音声認識が終了した際に呼ばれるコールバック
self.speech_recognizer.canceled.connect(self.canceled_callback)
def recognizing_callback(self,evt):
"""
継続中の音声認識結果を取得(確定前のテキスト)
"""
if evt.result.reason == speechsdk.ResultReason.RecognizingSpeech:
self.recognizing_text = evt.result.text
print(f"Recognizing: {evt.result.text}")
elif evt.result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized.")
def recognized_callback(self, evt):
"""
確定した音声認識結果を取得(確定後のテキスト)
"""
if evt.result.reason == speechsdk.ResultReason.RecognizedSpeech:
self.recognized_text = evt.result.text
print(f"Recognized: {evt.result.text}")
elif evt.result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized.")
def canceled_callback(self, evt):
"""
音声認識がキャンセルされたときの処理
"""
if evt.reason == speechsdk.CancellationReason.Error:
print(f"Speech Recognition canceled: {evt.error_details}")
def start_recognition(self):
"""
音声認識を開始
"""
print("音声認識を開始します(終了するには Ctrl+C を押してください)")
self.speech_recognizer.start_continuous_recognition()
def stop_recognition(self):
"""
音声認識を停止
"""
print("音声認識を停止します")
self.speech_recognizer.stop_continuous_recognition()
def get_recognized_text(self):
"""
外部から認識されたテキストを取得
"""
return self.recognized_text
def get_recognizing_text(self):
"""
外部から認識中のテキストを取得
"""
return self.recognizing_text
コールバック関数を活用した音声認識
1つめのポイントとして、Azure Speech SDKでは、非同期処理を効率的に行うためにコールバック関数が使われます。
各コールバック関数の役割は以下の通りです。コールバック関数を利用することで、リアルタイムな音声処理を効率的に実装できます。
recognizing: 音声が処理中の段階で部分的な認識結果を取得。recognized: 最終的な認識結果を取得。canceled: 認識がキャンセルされた場合の処理。
セマンティックセグメントの有効化
2つ目のポイントとして、自然なキャプションを生成するために、セマンティックセグメント(Semantic Segmentation)を有効化しています。これにより、単語単位ではなく、意味のまとまりとして音声を解析し、文脈を考慮した精度の高い認識が可能になります。
Speech SDKでは、音声の意味的な区切り(セグメント)を自動で判定し、適切なテキストに変換します。例えば、
- 「おはようございます。」 → 一つのまとまりとして認識
- 「おは よう ございます。」 → 不自然な分割を回避
セマンティックセグメントにより、実際の会話の流れを反映した認識結果が得られ、より自然なキャプションを生成することができます。
WebSocketを利用したHTMLの生成
音声認識の結果をテロップ化する方法を紹介します。WebSocketを使用し、PythonとHTMLでリアルタイムに通信を行い、動的にHTMLにテロップを生成します。
以下のプログラムでは、先ほど作成した音声認識処理をAISpeechとしてインポートして使用します。
import asyncio
import websockets
from AISpeech import AISpeech #先ほど作成した音声認識処理
class SpeechWebSocketServer:
def __init__(self):
self.ai_speech = AISpeech()
self.latest_recognizing_text = "" # 認識中のテキスト
self.latest_recognized_text = "" # 確定したテキスト
async def create_caption(self, websocket):
self.ai_speech.start_recognition()
try:
while True:
recognizing_text = self.ai_speech.get_recognizing_text()
recognized_text = self.ai_speech.get_recognized_text()
# 認識中のテキストが更新されたら送信
if recognizing_text and recognizing_text != self.latest_recognizing_text:
self.latest_recognizing_text = recognizing_text
await websocket.send(f"大沢:{recognizing_text}") # 認識中メッセージ
# 確定したテキストが更新されたら送信(認識中の表示を置き換える)
if recognized_text and recognized_text != self.latest_recognized_text:
self.latest_recognized_text = recognized_text
await websocket.send(f"大沢:{recognized_text}") # 確定メッセージ
await asyncio.sleep(0.1) # 負荷を抑えるためのスリープ
except asyncio.CancelledError:
self.ai_speech.stop_recognition()
print("音声認識を停止しました")
async def main():
server = SpeechWebSocketServer()
async with websockets.serve(server.create_caption, "localhost", 8765):
await asyncio.Future() # run forever
if __name__ == "__main__":
asyncio.run(main())
<body>
<p id="message"></p>
<script>
window.addEventListener("DOMContentLoaded", () => {
const websocket = new WebSocket("ws://localhost:8765/");
websocket.onmessage = ({ data }) => {
document.getElementById("message").innerHTML = data;
resetTimer();
};
});
</script>
</body>上記を実行し、HTMLを開くと音声を認識するようになります。マイクに対して話しかけると以下のようなキャプションがリアルタイムに生成されます。

以上のように、WebSocketを利用しHTMLファイルにリアルタイムに音声認識の結果を送信することで、シームレスに音声認識からキャプション生成まで行うことができます。
OBSを使用したカメラ映像とキャプションの合成とTeams会議での運用
最後に、OBSでカメラ映像とキャプションを合成し、Teamsでの会議で使用する方法を紹介します。
初めにOBSを起動し、ソースから映像キャプチャデバイスを選択し、使用したいカメラソースを選択します。次にソースからブラウザを選択し、先ほど作成したHTMLのパスを指定します。下の画像のに示すような2つのソースが認識されます。

次に、WebSocketサーバーを起動します。その後OBSで指定したブラウザソースを選択し、「再読み込み」を選択します。これによってWebSocketの通信が確立され、音声認識がされる状態になります。続いて仮想カメラ開始を押下し、OBSのカメラを起動します。このカメラをTeamsのカメラソースから選択することで、Teams会議上でキャプションを生成することができます。

仮想カメラを開始するとこのように表示されます

Teamsのビデオの設定からOBS VIrtual Cameraを選択すると、OBSの仮想カメラと接続することができます。
【動画】Teams会議上での様子
まとめ
Azure AI音声とOBSを使用したライブキャプションの生成について紹介させていただきました。話者に依存しますが、あまり発声を意識しなくてもうまく言葉を認識し、セマンティックセグメントによって自然なキャプションが生成される印象です。
OBSは簡単に様々な会議ツール、またYouTubeのような動画サービスのコンテンツからカメラソースとして呼び出せる為、システムに依存しないキャプション生成の仕組みを構築することができます。
また今回の方法を応用して、単に音声をリアルタイムでキャプション化するだけでなく、音声テキスト変換を利用したキャプション生成にも活用できそうです。
筆者
AIソリューショングループ
大沢直史
