ローカルLLMの推論を効率化するための実践的テクニック

はじめに
こんにちは、AIコンサルティンググループの中原輝樹です。
ここ数年で、研究機関や企業から強力なオープンソースの大規模言語モデル(LLM)が次々と登場しています。最近では、OpenAI o1モデルに匹敵する性能を誇るDeepSeek-R1がリリースされ、大きな話題となりました。このような発展に伴い、クラウド環境だけでなく、ローカル環境でのLLM運用にも関心が高まっています。

ローカル環境でのLLM運用は、個人情報や機密データを取り扱う企業にとって特に注目されています。インターネット接続が制限される環境でも利用でき、さらには用途に応じたカスタマイズが容易という特長があります。しかし、こうしたモデルをローカルで運用するには高性能なハードウェアが必要という課題があります。
本記事では、ローカルLLMの推論を高速化や、モデルを軽量化するための実践的なテクニックをご紹介します。具体的には以下の3つの手法について解説します。
- vLLM: PagedAttentionや効率的なバッチ処理を利用してLLMの推論を高速化するPythonライブラリ
- 量子化: モデルのパラメータをより少ないビット数で表現することで、モデルの軽量化や推論速度の向上を実現する手法
- LoRAレイヤーのアンサンブル: ファインチューニングによって得られた複数のLoRAレイヤーのパラメータを平均化することにより、推論速度を短縮しつつ精度を向上させる手法
それでは、それぞれの手法について詳しく見ていきましょう。
vLLM
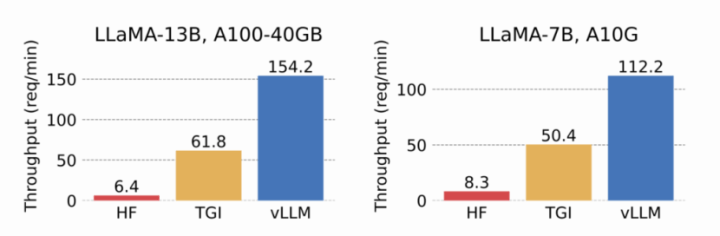
vLLMは、PagedAttentionや効率的なバッチ処理などによってLLMの推論を高速化するPythonライブラリです。ローカル環境でLLMを動かす際によく利用されるHugging FaceのTransformersライブラリと比較して、より高速な推論を実現できる点が大きな特長です。vLLMはHuggingFace Transformers (HF)と比べて14~24倍、HuggingFace Text Generation Inference (TGI)とと比べて2.2~2.5倍のスループットを発揮すると報告されています。
https://blog.vllm.ai/2023/06/20/vllm.html
実装方法
まずはLLMクラスを用いてモデルの初期化を行います。今回はmodelにLlama-3-ELYZA-JP-8Bを指定しています。enable_prefix_cachingをTrueにすることによって、システムプロンプトなど先頭に含まれる共通のプロンプトを持つクエリにおいて、事前入力処理(前処理フェーズ)を効率化し、推論速度を向上させることができます。特に、共通のプロンプト部分のトークン数が多い場合、推論の高速化の効果が高まります。
from vllm import LLM, SamplingParams
# モデルの指定
MODEL_NAME = "elyza/Llama-3-ELYZA-JP-8B" # 使用するモデル名
# モデル初期化
llm = LLM(
model=MODEL_NAME,
enable_prefix_caching=True, # クエリの処理時間を短縮
gpu_memory_utilization=0.90, # GPUメモリ使用率
)
# トークナイザ取得
tokenizer = llm.get_tokenizer()実験用の推論データを用意します。
# システムプロンプトの定義
SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。特に指示が無い場合は、常に日本語で回答してください。"
# 質問のリスト
questions = [
"世界で最も人口の多い国はどこですか?",
"太陽系で最も大きい惑星は何ですか?",
"シェイクスピアが書いた戯曲の中で最も有名な作品の1つで、「To be, or not to be」という台詞が含まれているのはどの作品ですか?",
"エベレスト山の標高はおよそ何メートルですか?",
"第二次世界大戦が始まった年と終わった年はそれぞれ何年ですか?",
"ノーベル平和賞を受賞した初の女性は誰ですか?",
"地球の表面積の約何%が水で覆われていますか?",
"アルベルト・アインシュタインが発表した有名な方程式E=mc^2は何を示していますか?",
"フランス革命が始まった年はいつですか?",
"人類が初めて月面に着陸したアポロ計画の名称とその年は?",
]
# システムメッセージの作成
system_message = [{"role": "system", "content": SYSTEM_PROMPT}]
# ユーザーメッセージを含む入力プロンプトの作成
inputs = [
system_message + [{"role": "user", "content": question}]
for question in questions
]
# チャットテンプレートをもとにプロンプトを作成
prompts = tokenizer.apply_chat_template(
inputs,
tokenize=False,
add_generation_prompt=True,
)SamplingParamsクラスでテキスト生成時の設定を定義し、その設定をもとに推論します。
# サンプリングパラメータの設定
sampling_params = SamplingParams(
temperature=0.9, # テキスト生成のランダム性
max_tokens=256 # 最大トークン数
)
# 推論の開始
results = llm.generate(prompts, sampling_params)
筆者の実行環境(RTX 4090)では、vLLMを使った推論が 4.74秒 で完了しました。一方、HuggingFace Transformers を使った場合は 23.88秒 かかりました。バッチ処理の有無などの違いで完全に同じ条件ではありませんが、vLLMの方が高速に推論できることがわかります。
量子化
量子化とは、モデルのパラメータをより少ないビット数で表現することで、モデルの軽量化や推論速度の向上を実現する手法の一つです。この技術により、リソースが限られた環境でもLLMを利用することが可能になります。量子化をサポートするライブラリとしては、bitsandbytes、AutoGPTQ、AutoAWQなどが広く知られていますが、今回は、まだ情報が少ない量子化ライブラリであるAutoRoundを用いた実装方法を紹介します。
auto-round:
https://github.com/intel/auto-round
実装方法
transformersを利用してモデルとトークナイザを読み込みます。
# モデルとトークナイザの読み込み
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
MODEL_NAME = "elyza/Llama-3-ELYZA-JP-8B"
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)量子化を行うためにはキャリブレーションデータと呼ばれるデータが必要です。量子化におけるキャリブレーションデータとは、モデルを量子化する際に精度を保つため、モデルが処理するデータに近いサンプルを使ってパラメータを調整するためのデータです。今回はELYZA-tasks-100を利用します。
# データセットの読み込み
dataset = load_dataset("elyza/ELYZA-tasks-100")
# システムプロンプトの定義
SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。特に指示が無い場合は、常に日本語で回答してください。"
# キャリブレーションデータの準備
calib_dataset = [
[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": dataset["test"][i]["input"]},
{"role": "assistant", "content": dataset["test"][i]["output"]}
]
for i in range(len(dataset["test"]))
]
# チャットテンプレートをもとにプロンプトを作成
calib_prompts = tokenizer.apply_chat_template(
calib_dataset,
tokenize=False,
add_generation_prompt=False, # 応答生成のためのプロンプトを追加しない
)量子化の設定を行います。今回は量子化ビット数を4とします。seqlenなどのパラメータは使用するモデル、データセットに応じて調整してください。そしてautoround.quantize()とするだけでモデルの量子化が実行されます。筆者の実行環境では10分ほどで量子化の処理が終わりました。
from auto_round import AutoRound
# 量子化の設定
bits, group_size, sym = 4, 128, True
autoround = AutoRound(model, tokenizer, bits=bits, group_size=group_size, sym=sym, dataset=calib_prompts, seqlen=256)
# モデルの量子化を実行
autoround.quantize()量子化されたモデルを保存します。save_quantizedメソッドの引数formatでエクスポート形式を指定できます。デフォルトのauto_round形式は現時点ではvLLMでサポートされていないため、量子化したモデルをvLLMで利用したい場合はエクスポート形式をauto_gptqやauto_awqに指定する必要があります。
# 量子化モデルを保存
output_dir = "./tmp_autoround"
autoround.save_quantized(output_dir, format='auto_gptq', inplace=True) 推論時にはvLLMを利用してモデルを読み込みます。modelに量子化モデルの保存先を指定します。先ほどエクスポート形式をauto_gptqにしたため、quantizationにgptqを指定します。
from vllm import LLM, SamplingParams
# モデル初期化
llm = LLM(
model="./tmp_autoround",
quantization="gptq",
gpu_memory_utilization=0.90, # GPUメモリ使用率
)
# トークナイザ取得
tokenizer = llm.get_tokenizer()プロンプトを作成し、推論を実行します。
# プロンプトを作成
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": "仕事で疲れた心をリフレッシュするためのアイデアを5つ挙げてください。"},
]
# チャットテンプレートをもとにプロンプトを作成
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# サンプリングパラメータの設定
sampling_params = SamplingParams(
temperature=0.9, # テキスト生成のランダム性
max_tokens=2048 # 最大トークン数
)
# 推論の開始
result = llm.generate(prompt, sampling_params)
# 結果の出力
print(result[0].outputs[0].text)出力結果
以下が出力結果です。比較のため、量子化を行わずに読み込んだモデルの出力結果も記載しています。量子化ありの出力では「自らをハグる」という表現が日本語として不自然ですが、それ以外には違和感が少なく、量子化の影響は限定的であることがわかります。
- 量子化あり
仕事で疲れた心をリフレッシュするためのアイデアを5つ紹介します:
1. 自然に触れる: 都会の喧騒を離れ、自然の力を借りて心を癒やします。森林浴、大自然の風景、山や海の近くに散歩、星空を眺めるなどが効果的です。
2. 運動する: 体を動かすことで血行が良くなる、ストレスが解消する、心がポジティブになることができます。散歩、ジョギング、ヨガ、ストレッチ、筋トレなどを試してください。
3. 趣味に没頭する: 賑やかで刺激的、好きなことにはまり、時間を忘れることでストレスを発散します。映画、音楽、読書、ペット、料理、絵画、スポーツなどが有効です。
4. リラクゼーション技法を学ぶ: 自宅でできるリラクゼーション法を学び、自らをハグることができます。アロママッサージ、ヘッドスパ、呼吸法、メディテーションなどを探してみてください。
5. 人と語る・自分と向き合う: 会話でストレスを解消し、内省することで新しい視点を手に入れます。カウンセリング、友人や家族と話す、日記やジャーナリングで自己の内面を観察することが効果的です。
いかがですか?疲れた心をリフレッシュする方法は、人によって異なるかもしれませんが、多くの人に効果的とされている方法です。- 量子化なし
仕事で疲れた心をリフレッシュするためのアイデアを5つ紹介します:
1. 自然に触れる: 都会の喧騒を離れ、自然の力を借りて心を癒やします。森林浴、大自然の風景、ビーチ、公園などで散歩や読書をしてリラックス。
2. 音楽を聴く: 好きな音楽を聴いて、心のストレスを解放します。特に、クラシックや癒やし系の音楽が効果的です。好きなアーティストやプレイリストを探してみましょう。
3. 笑いと笑顔: 笑う門には福来る、というように、笑うことで心が明るくなります。YouTubeの面白い動画、コメディ映画、友人とのおしゃべりなどで、心の緊張を解きほぐしてみましょう。
4. 簡単な運動を始める: 軽い運動で体を動かすと、血流がよくなり、心がスッキリします。散歩、ストレッチ、簡単な筋トレーニング、ヨガなど、無理のない範囲で始めてみてください。
5.自分を褒める: 達成感や自信を高めることで、心が充実します。日々の小さなことを積み重ねて、自分を褒めましょう。例えば、仕事で頑張った部分、家事をきちんとこなした部分など、自分を認め、褒めることを習慣化してみてください。
これらのアイデアを組み合わせて、自分に合ったリフレッシュ方法を見つけることが大切です。LoRAレイヤーのアンサンブル
LoRAは、LLMの効率的なファインチューニングを実現する手法です。ファインチューニング時にデータセットをN分割し、交差検証を行うと、N個のLoRAレイヤーが得られます。しかし、これらをすべて利用すると推論時間が増加してしまいます。そこで、得られたLoRAレイヤーのパラメータを平均化するなどしてアンサンブルすることで、推論速度を単純計算で1/Nに短縮しつつ、アンサンブルによる精度向上効果も得ることができます。
この手法は、特にKaggleのコンペティションにおいて活用されており、限られた推論リソースの中で精度を向上させるための有効なアプローチとなっています。
実装方法
対応するキーごとにパラメータを平均して保存するだけ完了です。あとはLoRAの重みを元のモデルに統合して利用できます。
import torch
# LoRAレイヤーの読み込み
adapter1 = torch.load("./fold0/adapter.bin")
adapter2 = torch.load("./fold1/adapter.bin")
# 平均化
avg_adapter = {}
for key in adapter1.keys():
avg_adapter[key] = (adapter1[key] + adapter2[key]) / 2.0
# 保存
torch.save(avg_adapter, "avg_adapter.bin")まとめ
本記事では、ローカル環境でのLLMの運用における推論の高速化とモデルの軽量化に関する実践的なテクニックを紹介しました。特に、vLLMを用いた推論の高速化、量子化技術を活用したモデルの軽量化、そしてLoRAレイヤーのアンサンブル手法について解説しました。
今後、LLMの活用がますます広がる中で、これらの技術を駆使することで、より高性能なAIシステムの構築が可能となります。
また、AITCでは共に働いてくださるメンバーを募集しています。本記事を読んで、AITCの活動に興味を持っていただけますと幸いです。
下記のページにAITCでの働き方や募集職種、組織などの採用に関わる情報をまとめています。 カジュアル面談の応募フォームもこちらのページにリンクがありますのでぜひご覧ください。

筆者
AIコンサルティンググループ
中原輝樹