Kaggleにおける生成AIエージェント②:マルチエージェントはデータ分析を自動化できるのか?その仕組みと適用例
はじめに
こんにちは。Kaggle Masterの阿田木です。
本記事はKaggleにおける生成AIエージェント①の続編になります。

前回はReAct等のシングルエージェントを中心に紹介しました。
今回はマルチエージェント、特にLLMを活用したマルチLLMエージェントシステムについて解説します。
また、データ分析のプロセスをサポートするためのマルチエージェントフレームワークであるAutoKaggleについても解説し、Kaggle におけるマルチエージェントの適用可能性を深堀りしたいと思います。
※AutoKaggleに関しては、AITC のコンサルティングGの清水さんが、調査、検証、執筆しています。
マルチLLMエージェントシステム(MLAS)の概要
1. MLAS(マルチLLMエージェントシステム)とは?
MLAS(Multi-LLM-Agent Systems)とは、複数の大規模言語モデル(LLM)を活用するエージェントを連携させて、タスクを遂行・問題解決するシステムです。各エージェントは自律的に振る舞いつつ、他のエージェントからの入力や知見を取り込み、複雑なタスクを協調しながら処理します。
2. MLASの代表的なアーキテクチャ
MLASの実装にあたっては、まず要件定義とアーキテクチャ選定が重要になります。
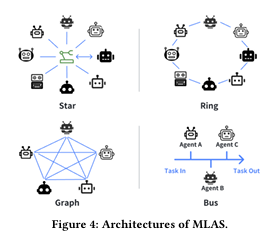
論文「Multi-LLM-Agent Systems: Techniques and Business Perspectives」では、MLASを以下の4つの構造に分類しています。ネットワークトポロジーに近い構成が特徴的です。
※ LangGraphからもマルチエージェントアーキテクチャパターンが紹介されています。今回ご紹介するアーキテクチャパターンとも共通点が多いため、一部抜粋してご紹介いたします。
2.1 スター型(Star Architecture)
中央オーケストレーター が全体の制御を行い、各エージェント間の通信はオーケストレーターを介して行われるアーキテクチャです。
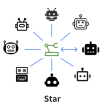
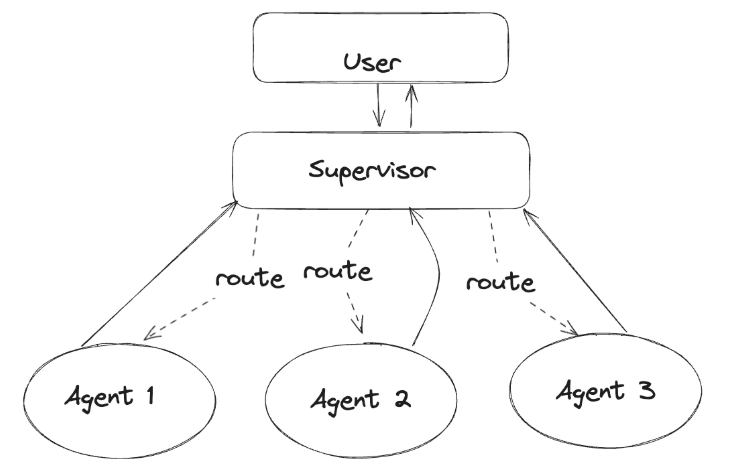
LangGraphでは、Supervisor(中央管理)型として紹介されており、実装例も公開されています。
※ LangGraphでcreate_supervisorが実装されたためlanggraph_supervisor モジュールからインポートして簡単にSupervisorエージェントを作成できるようになりました
- 特徴
- 管理しやすく、システム全体の状況を中央で把握できる
- 中央に負荷・責任が集中するリスクがある
- 適用シナリオ
- 中核となる指令・調整役(司令塔)が必要 なプロジェクト
- エージェントの個別最適よりも、全体最適を重視するタスク
2.2 リング型(Ring Architecture)
エージェントがリング状に接続され、情報やタスクが 一方向または双方向 に巡回しながら処理されるアーキテクチャです。

- 特徴
- データやタスクが 段階的・逐次的 に処理される
- 1つのエージェントに障害が発生するとリング全体に影響しやすい
- 適用シナリオ
- 段階的処理 が明確なタスクフロー(例:入力→前処理→分析→出力)
- パイプライン構造がわかりやすいワークフロー
2.3 グラフ型(Graph Architecture)
エージェント同士が 自由に接続 でき、多方向の通信が可能な柔軟な構造です。

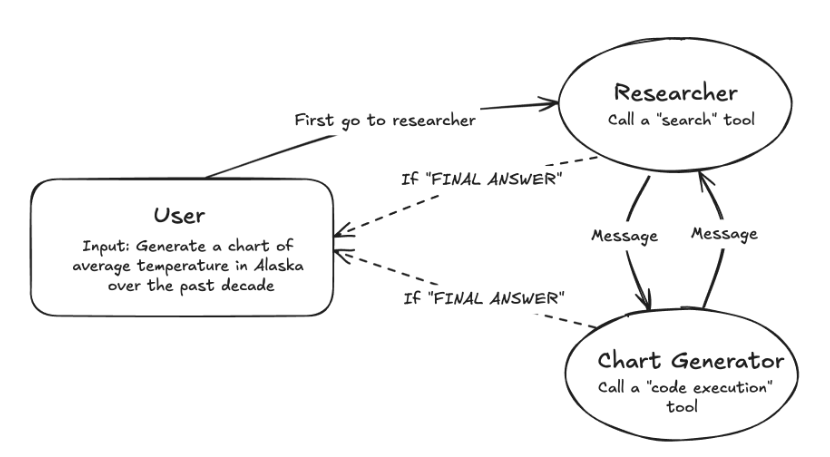
LangGraphでは、Network型としても紹介されており、実装例も公開されています。
- 特徴
- 高い柔軟性・拡張性
- 連携パターンが複雑になり、制御が難しくなる可能性
- 適用シナリオ
- 動的な相互作用 が頻繁に発生するタスク
- 多数のエージェントが同時並行で情報交換するケース
2.4 バス型(Bus Architecture)
共通の通信バス を用いてエージェントが情報をやりとりし、イベントドリブンでタスクを割り振るアーキテクチャです。
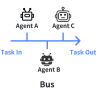
- 特徴
- 標準的なプロトコルや手順を用いた連携が可能
- バスに接続してさえいれば、エージェントの追加・削除が比較的容易
- 適用シナリオ
- IoTやエンタープライズ系 など、標準プロトコルに基づくシステム
- エージェントの数が増減しやすいダイナミックな環境
ここまで紹介した4つのアーキテクチャは、マルチLLMエージェントシステムを設計する上で大まかな「接続構造」を示すものです。しかし実際には、これらの構造をどう実装し、エージェント同士の連携をどのように最適化すればよいかが重要になってきます。
次のセクションでは、マルチLLMエージェントを構築・運用する際に役立つ「実装パターン」について取り上げます。各アーキテクチャと組み合わせることで、具体的なタスクの割り振り方法やエージェント間の相互作用の改善に応用できます。
3. マルチLLMエージェントにおける実装パターン
AIエージェント設計のためのデザインパターンは、「Agent Design Pattern Catalogue: A Collection of Architectural Patterns for Foundation Model based Agents」で18種類が紹介されています。
ここでは、その中からマルチLLMエージェントに関連する代表的なパターンを取り上げます。
3.1 役割分担型協力(Role-based Cooperation)
主にスター型のような中央リーダーとサブエージェントの構造と親和性が高いパターンです。
- 概要
- 中央エージェントがタスクを割り振り、各エージェントが専門分野に応じて処理を担当
- メリット
- タスクと役割が明確になり、管理しやすい
- デメリット
- 中央に負荷や責任が集中しがち
3.2 反映型協力(Reflection)
リング型 のように順番に処理を回す構造との親和性が高いパターンです。
- 概要
- あるエージェントが出した解決策を、別のエージェントがレビューしフィードバックを行う
- メリット
- フィードバックを重ねることで、解が継続的に改善される
- デメリット
- フィードバックを経るため、処理に時間がかかる場合がある
3.3 投票型協力(Voting-based Cooperation)
グラフ型 など、多数のエージェントが同時に解を出せる構造との相性が良いパターンです。
- 概要
- 複数エージェントが各自の提案を出し、投票や合意形成によって最適解を選択
- メリット
- 多面的な視点が得られ、精度が向上する可能性がある
- デメリット
- 投票ルールの設定や重み付けの調整など、設計が複雑になりやすい
データ分析エージェント(AutoKaggle)の紹介
AutoKaggleは、データ分析のプロセスをサポートするためのマルチエージェントフレームワークです。特に、世界的なデータサイエンスコンペティションであるKaggleにおける課題解決を支援するために設計されています。
本フレームワークは、役割分担されたエージェントを活用し、データの前処理、特徴エンジニアリング、モデル構築などのタスクを自動化します。
Kaggleコンペティションの取り組みにおいて、AutoKaggleを用いた実験の結果、有効提出率と平均スコアを指標とした総合スコア0.82を達成し、高いパフォーマンスを示しました。
AutoKaggleの特徴
AutoKaggleは、マルチエージェントの構成をとっており、データサイエンスにおける各工程ごとの処理を段階的に実行しています。
[2410.20424] AutoKaggle: A Multi-Agent Framework for Autonomous Data Science Competitions
AutoKaggleは、以下の特徴を持ちます。
- 反復的な開発プロセスと包括的なテストを組み合わせ、Kaggleコンペティションの取り組みを自動化。
- 機械学習ツールライブラリの統合により、コードの生成効率と品質を向上。
- 各工程ではユーザーがカスタマイズ可能なワークフローを提供し、Human-in-the-Loopを実現。
- 各フェーズのレポートを自動生成し、実施した方針や結果を可視化。
これにより、AutoKaggleはKaggleコンペティションの自動化ツールとしてだけでなく、データサイエンスの学習ツールとしても活用可能です。
AutoKaggleのアーキテクチャ
アーキテクチャ概要
AutoKaggleは、基本的なデータサイエンスの工程(データクリーニング、特徴エンジニアリング、モデル構築・予測)に加え、データの概要や目標といった背景理解のフェーズ(Background Understanding)と二つのデータの分析フェーズ(1. Preliminary EDA, 3. In-depth EDA)が追加されています。
5つのエージェント(Reader, Planner, Developer, Reviewer, Summarizer)が協力し、問題分析から結果のレポート生成までを担当します。
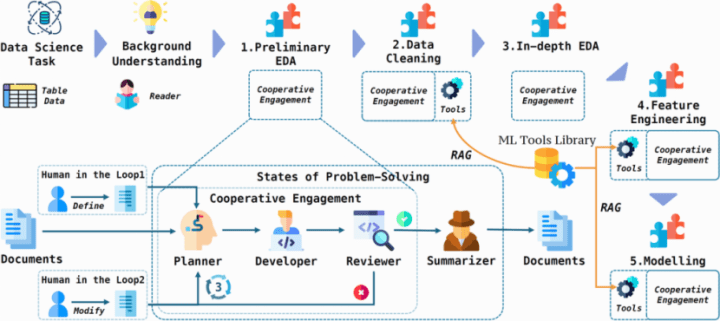
アーキテクチャの詳細
AutoKaggleは、スター型アーキテクチャを基盤にしつつ、エージェント同士の情報共有を強化するためグラフ型の要素を取り入れた設計になっています。
| エージェント | 役割 |
|---|---|
| Reader | データセットとコンペティションの要件を解析し、入力情報を抽出 |
| Planner | 全体の進行を管理し、タスクを他のエージェントに割り振る |
| Developer | データの前処理、特徴エンジニアリング、モデル構築を担当 |
| Reviewer | Developer が作成したコードや処理結果を評価し、フィードバックを提供 |
| Summarizer | 各工程の結果を統合し、最終レポートを作成 |
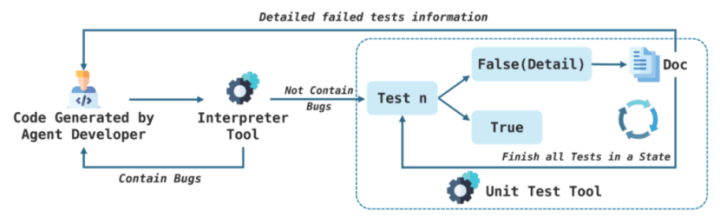
コード生成部分において、エラーが発生した場合に、Developerが反復的にデバッグを行う設計になっています。
そしてエラー解消後、著者らが作成したユニットテストを通過することで、コード生成を安定化させています。
さらに、工程ごとの機械学習ツールを作成し、フレームワークに統合させて、コードの生成効率や品質を向上させています。
実行結果
最終結果として生成されたsubmission.csvをタイタニックのコンペに提出したところ、スコアは0.76でした。
(LLMはGPT-4o-miniを使用しました)
報告レポート
# コンペティション調査レポート
## 1. 予備的なEDA
予備的な探索的データ分析(EDA)フェーズでは、特徴を調査し、データセットの主要な特性を特定しました。データセットは、ターゲット変数「Survived」を含む12の特徴で構成されていました。注目すべき発見は以下の通りです:
- **欠損値**: 「Age」特徴には約19.9%の欠損値があり、「Cabin」には約77.1%の欠損値がありました。これは、分析に影響を与える可能性のあるデータの大きなギャップを示唆しています。
- **外れ値**: 「Fare」特徴には顕著な外れ値が存在し、高額支払いの乗客がいる可能性を示しています。一方、「Age」の分布は右に歪んでいました。
- **生存率の洞察**: 生存率は性別(女性の生存率が高い)およびクラス(1等客の生存率が高い)によって大きく影響されました。
取られた行動には、将来の分析とデータクリーニングのステップを通知するための特徴の詳細な視覚的探索が含まれ、特に欠損値と外れ値に対処する方法に焦点を当てました。
## 2. データクリーニング
データクリーニングフェーズでは、欠損値に対処し、データ型を標準化して分析の準備を行いました。主な行動は以下の通りです:
- **補完**:
- 「Age」の欠損値は中央値で補完しました。
- 「Embarked」の欠損値は最頻値で補完しました。
- 「Fare」の欠損値も同様に中央値で補完しました。
- **特徴の削除**: 「Cabin」特徴は過剰な欠損値(50%以上)のため削除しました。
- **データ型の標準化**: 「Pclass」、「Sex」、「Embarked」などのカテゴリカル特徴は「category」型に変換し、一貫性を確保しました。
これらの行動は、ノイズを減らし、このデータで訓練されたモデルがより信頼性が高く解釈可能になるようにするために重要でした。
## 3. 詳細なEDA
詳細な探索的データ分析では、特徴間のより複雑な関係と生存に対する影響が明らかになりました:
- **単変量分析**: 要約統計は、年齢と運賃の分布が右に歪んでいることを示し、変換の必要性を強調しました。
- **二変量分析**: 関係性は、若い乗客と高額運賃を支払った乗客がより高い生存率を持つことを示しました。特に1等客の女性は最も高い生存確率を持っていました。
- **相互作用**: 乗客クラスと性別の間に重要な相互作用が見られ、生存に影響を与える複雑な相互作用があることが示されました。
これらの発見は特徴エンジニアリングフェーズを導き、相互作用特徴を作成し、モデル性能を向上させるための変換を考慮する必要性を強調しました。
## 4. 特徴エンジニアリング
このフェーズでは、前のフェーズから得られた洞察に基づいて新しい特徴を作成し、既存の特徴を変換することに焦点を当てました:
- **変換**: 「Age」と「Fare」に対して対数変換を適用し、分布を正規化しました。
- **ビニング**: 運賃と年齢のカテゴリカル特徴をそれぞれ分位数と年齢グループに基づいて作成し、解釈性を向上させ、トレンドを捉えました。
- **相互作用特徴**: 「Pclass_Sex」や「Age_Pclass」などの新しい特徴を作成し、これらの変数の組み合わせが生存に与える影響を捉えました。
これらのエンジニアリングされた特徴は、データの複雑な関係を反映するより情報量の多い入力を提供することで、モデルの予測能力を向上させるように設計されました。
## 5. モデル構築、検証、および予測
ロジスティック回帰、ランダムフォレスト、勾配ブースティングを含む複数のモデルを訓練しました。主な発見は以下の通りです:
- **モデル性能**:
- ロジスティック回帰は検証精度0.4134で低い性能を示しました。
- ランダムフォレストと勾配ブースティングはそれぞれ0.8101と0.8156の高い精度を達成し、データの基礎的なパターンを効果的に捉えていることを示しました。
- **特徴の重要性**: 予測に影響を与える主要な特徴には「Age」、「Fare」、「Pclass」、「Sex」が含まれました。
- **過学習防止**: 訓練-検証分割などの手法を使用して、堅牢なモデル評価を確保しました。
最終モデルは勾配ブースティングに基づいており、最良の性能を示し、最終予測フェーズに進みました。
## 6. 結論
調査プロセスは、タイタニックの生存を理解し予測するための構造化されたアプローチを含んでいました。主要な洞察には、社会経済的要因(クラス、運賃)および人口統計学的特性(年齢、性別)が生存率に強く影響することが含まれていました。最も影響力のある決定には以下が含まれます:
- データセットの品質を向上させるために欠損値と外れ値に効果的に対処すること。
- 複雑な関係を捉える意味のある特徴をエンジニアリングし、モデル性能を向上させること。
- 信頼性の高い予測を提供する堅牢なモデルを選択し、検証すること。
全体として、徹底的な探索的分析、慎重なデータクリーニング、および戦略的な特徴エンジニアリングの組み合わせにより、テストデータセットに対する正確な予測を達成する成功したモデリングフェーズに至りました。結果の考察
論文の平均値は0.776だったので、同じくらいでしょうか。入門的なコンペなのと、既にGPT自体はコンペの概要自体学習済みなのでもう少し上げられそうですが、実行時間25分で完了していたのでそれを考えるとかなり価値はありそうです。また、一連の工程を自動でコーディングし、報告レポートの作成まで行っており、kaggle序盤のサポート役として非常に有望です。
Kaggleでの活用検討
対象のデータは表形式のデータである必要があります。また、LLMをエージェントとして使うため、外部のapiを使える必要もあります。
ベースラインのコードを実行したり、Jupyter Notebookを使うことは想定されていないようです。ベースラインを実行するようなツールを作成する必要があるかもしれません。
また、最初にコンペの概要を読み込ませていますが、実際のdiscussion内容などもoverview.txtなどに書くとより精度が上がりそうです。
まとめ
本記事では、Kaggleにおける生成AIエージェントの第2弾として、LLM(大規模言語モデル)を活用したマルチLLMエージェントシステム(MLAS)について解説しました。さらに、データ分析プロセスを支援するマルチエージェントフレームワーク「AutoKaggle」も紹介し、Kaggleにおけるマルチエージェントの適用可能性を検証しました。
MLASは、複数のLLMエージェントが協調してタスクを遂行するシステムであり、スター型、リング型、グラフ型、バス型といった代表的なアーキテクチャがあります。各アーキテクチャには、中央制御の有無やエージェント間の通信方法など、それぞれ特徴と適用シナリオが存在します。
AutoKaggleは、データサイエンスの各工程(データクリーニング、特徴エンジニアリング、モデル構築・予測)を自動化するためのマルチエージェントフレームワークです。5つのエージェント(Reader、Planner、Developer、Reviewer、Summarizer)が協力し、問題分析から結果のレポート生成までを担当します。実験結果では、Kaggleコンペティションにおいて最低限のベースラインを作成できることを示し、データサイエンスの学習ツールとしても有望であることが確認されました。
一方で、実際のKaggleコンペで活用するには精度の面では不十分なため、改善に特化したエージェントが別途必要とされます。そのためには、LLMの進化を待つだけでなく、今回紹介したアーキテクチャや実装パターンをうまく組み合わせて、さらに発展的なマルチエージェントを構築する必要があります。
これらのマルチLLMエージェントシステムの導入により、Kaggleにおけるデータ分析の自動化と効率化が期待されます。今後、マルチLLMエージェントの活用がKaggleの競争環境やデータサイエンスの実践にどのような影響を与えるか、注目されます。
次回は、AITCにおける、生成AIエージェントを活用したKaggleの取り組みについてご紹介します。
お楽しみに!
筆者
AIソリューショングループ
阿田木 勇八

