Snowflake CortexAIの Cortex COMPLETE Multimodalを使ってみた

はじめに
こんにちは、AIコンサルティンググループの桝田修慎です。
Snowflakeはクラウド型のデータウェアハウスにとどまらず、AI活用における強力な基盤へと進化しています。
Snowflakeでは生成AIの機能群としてCortex AIを提供しており、その中でも2025年4月にパブリックプレビューになったCOMPLETE Multimodal機能は、Snowflakeでビジョンタスク(画像分類, エンティティ検出, キャプション生成, etc.)の実行を可能にしました。
これまで、Snowflake上でビジョンタスクを実行するためには、外部サービスや複雑なシステムの連携が必要で、データ移動コストやセキュリティリスクなど多くの課題が存在していました。さらに、複数のサービスを組み合わせることで運用が煩雑になり、スムーズな導入と継続的な活用に苦労するケースも少なくありませんでした。
しかしこれからは、Cortex COMPLETE Multimodalのように、Snowflake内で画像分析といった高度なAI機能を一元的に利用できる環境が新たなスタンダードになっていきます。外部APIを介さずに安全かつシンプルに実行できるため、データガバナンスを維持しながらスピーディにAI活用を進めることが可能となります。
この記事では、Cortex COMPLETE Multimodalの概要を紹介した後、機能を組み込んだ簡易的な画像処理アプリケーションを作成することでさらに理解を深めます。一緒にSnowflake×ビジョンタスクの可能性を探ってみましょう。
Cortex COMPLETE Multimodalとは?
ユーザーからの画像とプロンプト入力に対して、言語モデルを用いて応答を生成できる機能のことです。Snowflakeの内部・外部ステージに画像をアップロードすることで、単一・複数の画像を処理し結果を返すことができます。
具体的には、わずか数行のSQLで以下のようなビジョンタスクと呼ばれるAIによる画像処理の実行が可能になります。
- 画像の比較
- 画像のキャプション生成
- 画像の分類
- 画像からのエンティティ抽出
- グラフやチャートのデータを使用して質問に答える
対応しているモデルとリージョン
細かな制限はありますが、2025年6月時点では7つのモデルがAWSの3つのリージョンで利用可能です。
| モデル | AWS 米国西部 2(オレゴン) | AWS 米国東部 1(バージニア州北部) | AWS ヨーロッパ セントラル 1(フランクフルト) |
|---|---|---|---|
claude-3-5-sonnet | ✔ | ✔ | |
claude-3-7-sonnet *1 | |||
claude-4-sonnet *1 | |||
claude-4-opus *1 | |||
pixtral-large | ✔ | ✔ | ✔ |
llama4-maverick | ✔ | ||
llama4-scout | ✔ |
*1:クロスリージョン推論を通じてのみ利用可能です。
入力要件
入力画像に対する要件は以下の通りです。
| 要件 | 値 |
|---|---|
| ファイル名拡張子 | .jpg, .jpeg, .png, .webp, .gif |
| ステージ暗号化 | サーバー側の暗号化 |
| データ型 | ファイル |
※執筆時点(2025/06/05)では、pixtral-largeとllamaモデルのみ、追加で.bmpに対応しています。
使い方
画像を保存するためのステージの作成
Cortex COMPLETE Multimodalを利用するためには、分析対象の画像をアップロードするための場所(ステージ)を用意する必要があります。
内部ステージの場合
CREATE OR REPLACE STAGE input_stage
DIRECTORY = ( ENABLE = true )
ENCRYPTION = ( TYPE = 'SNOWFLAKE_SSE' );外部ステージの場合
CREATE OR REPLACE STAGE input_stage
URL='s3://<s3-path>/'
CREDENTIALS=(AWS_KEY_ID=<aws_key_id>
AWS_SECRET_KEY=<aws_secret_key>)
ENCRYPTION=( TYPE = 'AWS_SSE_S3' );Cortex COMPLETE Multimodalの実行
Cortex COMPLETE Multimodalを実行するためには、COMPLETE関数の引数としてモデル名・分析クエリ・画像が格納されているステージの情報を与える必要があります。
単一画像に対してタスクを実行する場合
SELECT SNOWFLAKE.CORTEX.COMPLETE('claude-3-5-sonnet',
'Summarize the insights from this pie chart in 100 words',
TO_FILE('@myimages', 'science-employment-slide.jpeg'));複数画像に対してタスクを実行する場合
SELECT SNOWFLAKE.CORTEX.COMPLETE('claude-3-5-sonnet',
PROMPT('Compare this image {0} to this image {1} and describe the ideal audience for each in two concise bullets no longer than 10 words',
TO_FILE('@myimages', 'adcreative_1.png'),
TO_FILE('@myimages', 'adcreative_2.png')
));
実装
今回作成するアプリケーションは、ユーザーが入力したテキスト(説明や質問など)をもとに、1枚または2枚の画像に対して自動的に内容を分析・解釈できるというものです。
開発に利用する技術とアプリケーションの完成イメージを紹介し、実装のポイントを説明していきます。
開発に利用する技術
Cortex COMPLETE Multimodal を活用した画像処理を、Streamlit と Snowpark Python を組み合わせて実現しました。それぞれの技術スタックは以下の役割を担っています。
Cortex COMPLETE Multimodal
claude-3-5-sonnetなどの大規模言語モデルをSnowflakeから直接呼び出し- 画像と言語の統合処理(キャプション生成・比較など)を実行
Snowpark Python
- Snowflakeとの安全なセッション管理
- SQLコマンドをPythonで実行
- Snowflake内部ステージへのファイルアップロード
- Cortex関数の実行と結果の取得
Streamlit
- ローカル画像を簡単に選択してアップロード
- 画像に対する自然言語の指示をGUI上で記述
- Cortex AIからの応答を即座に可視化
- 単一画像処理/複数画像比較をタブで切り替え
アプリケーションの完成イメージ
Snowpark Pythonによるセッション・オブジェクト作成、ファイルアップロード
snowflake.snowparkのSessionを使ってセッションを作成します。
def get_snowpark_session():
connection_parameters = {
"account": os.environ["SNOWFLAKE_ACCOUNT"],
"user": os.environ["SNOWFLAKE_USER"],
"password": os.environ["SNOWFLAKE_PASSWORD"]
}
return Session.builder.configs(connection_parameters).create()sql()を使ってデータベース・スキーマ・ウェアハウス・(内部)ステージを作成します。ステージ作成時はディレクトリテーブルの有効化、暗号化のタイプを指定しましょう。
def init_snowflake_object(session):
db = os.environ["SNOWFLAKE_DATABASE"]
schema = os.environ["SNOWFLAKE_SCHEMA"]
stage = os.environ["SNOWFLAKE_STAGE"]
wh = os.environ["SNOWFLAKE_WAREHOUSE"]
sql_statements = [
f"CREATE OR REPLACE DATABASE {db};",
f"CREATE OR REPLACE SCHEMA {db}.{schema};",
f"CREATE OR REPLACE WAREHOUSE {wh};",
f"USE DATABASE {db};",
f"USE SCHEMA {schema};",
f"USE WAREHOUSE {wh};",
f"""
CREATE OR REPLACE STAGE {stage}
DIRECTORY = ( ENABLE = true )
ENCRYPTION = ( TYPE = 'SNOWFLAKE_SSE' );
"""
]
for sql in sql_statements:
session.sql(sql).collect()PUTコマンドを使って、前手順で作成した内部ステージへファイルをアップロードします。
put_sql = f"""
PUT 'file://{tmp_file_path}'
@{os.environ["SNOWFLAKE_DATABASE"]}.{os.environ["SNOWFLAKE_SCHEMA"]}.{os.environ["SNOWFLAKE_STAGE"]}
AUTO_COMPRESS=FALSE
"""
result = session.sql(put_sql).collect()Streamlitによる画面作成
Streamlitのtabsを使って、2つのモードを切り替えられるようにします。
import streamlit as st
from dotenv import load_dotenv
from snowflake.session_manager import get_snowpark_session
from snowflake.object_initializer import init_snowflake_object
from mode.single import single_image
from mode.multiple import multiple_images
def init_page():
st.set_page_config(
page_title="Cortex COMPLETE Multimodal Demo",
page_icon="❄️"
)
st.header("Cortex COMPLETE Multimodal Demo ❄️")
st.markdown("""
SnowflakeのCortex COMPLETE Multimodal機能を使用して、画像処理タスクを実行します。
https://docs.snowflake.com/en/user-guide/snowflake-cortex/complete-multimodal
""")
def main():
init_page()
if "session" not in st.session_state:
session = get_snowpark_session()
init_snowflake_object(session)
st.session_state["session"] = session
tabs = st.tabs(["SINGLE", "MULTIPLE"])
with tabs[0]:
single_image()
with tabs[1]:
multiple_images()
if __name__ == "__main__":
main()Cortex COMPLETE Multimodalによる画像処理
単一画像の場合:Streamlitからユーザーの入力を受け取り、COMPLETEに与えて処理を実行します。モデルはclaude-3-5-sonnetを使います。
user_prompt = st.text_area("プロンプトを入力してください", "100文字程度でキャプションを生成してください。")
if st.button("実行", key="single_image"):
try:
with st.spinner("処理中…"):
result = session.sql(f"""
SELECT SNOWFLAKE.CORTEX.COMPLETE('claude-3-5-sonnet',
'{user_prompt}',
TO_FILE('@{os.environ["SNOWFLAKE_STAGE"]}', '{os.path.basename(tmp_file_path)}'));
""").collect()
st.subheader("結果")
st.write(result[0][0])
except Exception as e:
st.error(f"処理中にエラーが発生しました: {e}")複数画像(2枚)の場合:アップロードしたファイルの情報をリストで保持しているので、それぞれTO_FILEに引数として与えます。
user_prompt = st.text_area("プロンプトを入力してください", "2つの画像の違いを説明してください。")
if st.button("実行", key="multiple_images"):
try:
with st.spinner("処理中..."):
result = session.sql(f"""
SELECT SNOWFLAKE.CORTEX.COMPLETE('claude-3-5-sonnet',
PROMPT('2つの画像 {{0}} と {{1}} に対し、ユーザーの指示に従って処理してください。指示は次の通りです: {user_prompt}',
TO_FILE('@{os.environ["SNOWFLAKE_STAGE"]}', '{os.path.basename(file_path[0])}'),
TO_FILE('@{os.environ["SNOWFLAKE_STAGE"]}', '{os.path.basename(file_path[1])}')));
""").collect()
st.subheader("結果")
st.write(result[0][0])
except Exception as e:
st.error(f"処理中にエラーが発生しました: {e}")完成したアプリケーション
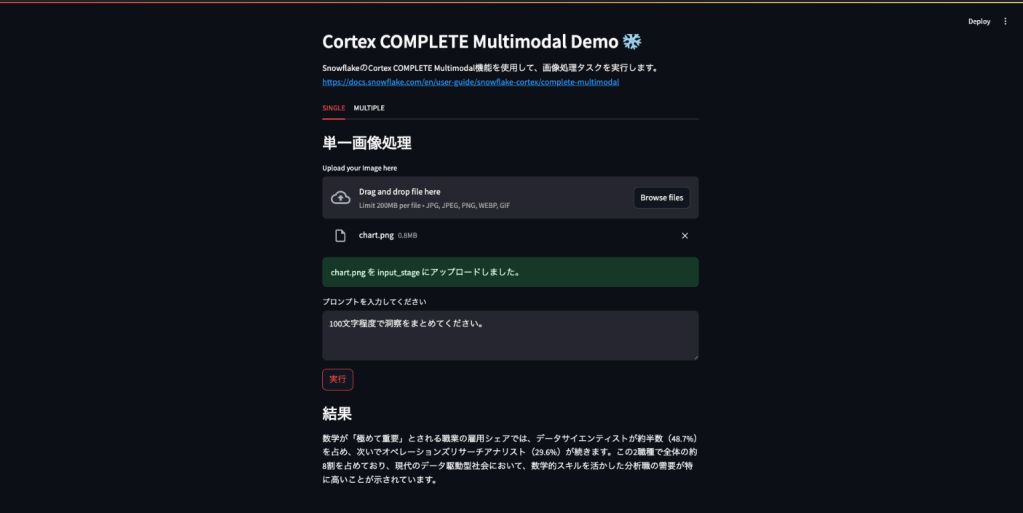
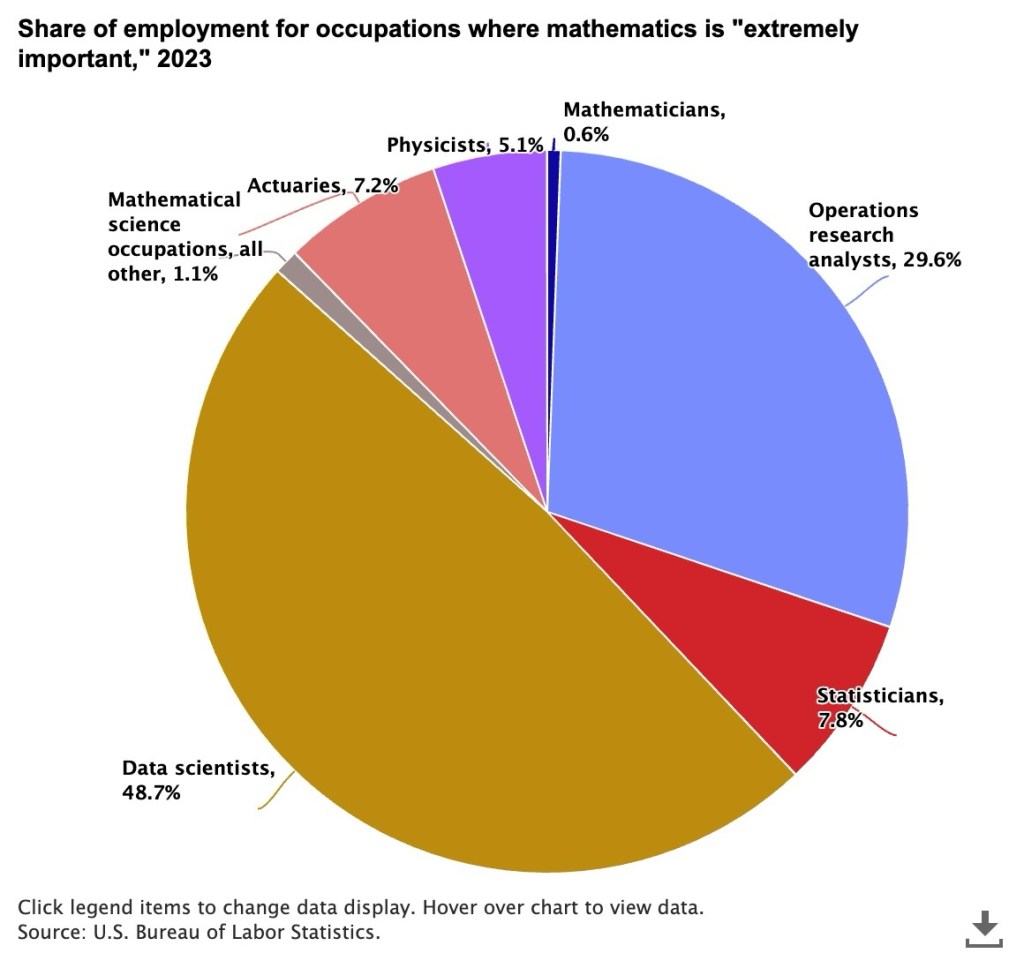
実装したアプリケーションを動かしてみます。入力画像はCortex COMPLETE Multimodalの紹介ページに掲載されていた、円グラフと広告クリエイティブ2種類を使います。円グラフは、「数学が極めて重要視されている職業の雇用シェア」の比率が示されています。データサイエンティストが最も高いですね。広告クリエイティブは、どちらも車の画像とキャッチコピーが描かれていますが、それぞれキャッチコピーや色合いが違います。これらを適切に認識できるでしょうか。


デモ
単一画像処理
「100文字程度でキャプションを生成してください。」という指示に対して、「データサイエンティストが約半数を占めていて、48.7%」「次いでオペレーションズリサーチアナリストが29.6%」のような正しいキャプションを生成できました。
複数画像処理
「2つの画像の違いを説明してください」という指示に対して、「DISCOVER A NEW ENERGY」「ELECTRIFY YOUR DRIVE」を正しく認識し、背景の特徴の説明、雰囲気の違いをしっかりと生成できているようです。
ビジネスでの活用例
ここでは、オンラインストアでの売上が伸び悩んでいるアパレル小売企業を例に、Multimodal機能のビジネス活用について考えてみます。
データ
Snowflake上で画像の分析が可能になったことで、従来の構造化データ(購入履歴や閲覧履歴)に加え、オンラインストアに掲載している商品画像のような視覚データ(衣服の画像)を統合して分析することができます。
分析方針
オンラインストアに掲載している商品画像と購入履歴や閲覧履歴の関係を分析すると、何か売上アップに繋がる洞察が得られるかもしれません。Multimodal機能を用いて画像内の背景色・モデルの着用画像の有無を分類し、構造化データと組み合わせて分析してみます。
分析結果
Cortex COMPLETE Multimodalにより分析により、例えば以下のような「視覚要素が購入に与える影響」をAIが提示することができます。
- 白背景で明るい照明の写真は閲覧数が多く、暗い背景の商品に比べて購入率が20%高くなる
- モデルが着用している写真の方が、商品単体の画像より3倍購入されやすい
改善策
分析結果をもとに、以下のような改善策を掲げることができます。
- 商品画像の背景の色味を明るいものに差しかえ
- 商品単体の画像を極力減らし、モデル着用画像のある商品を充実させる
改善策を上手く適用できると...
オンラインストアの平均滞在時間が伸び、全体売上の向上につながりました。
この例はあくまで架空のオンラインストアを想定した運用例ですが、実際のビジネスにおいてもMultimodal機能によってSnowflake上でのデータ活用の幅が大きく広がることがイメージできたと思います。
まとめ
SnowflakeのCortex COMPLETE Multimodalを活用し、Snowflake上で画像を手軽に分析できるアプリケーションを作成しました。
これまで社内で蓄積されているだけだった画像データに対しても、Multimodal機能を使って簡単に分析が可能となり、業務に大きなインパクトを与える洞察を引き出せる可能性があります。
さらに、Cortex AnalystやCortex Agentsといった Snowflake の強力なAI機能と組み合わせることで、より便利で賢い業務支援ツールや自動化された分析基盤を構築可能であり、業務効率化や意思決定の高度化に貢献します。
ご相談事項があればお気軽に問い合わせしていただければと思います。

執筆
AIコンサルティンググループ
桝田修慎

