動画コンテンツ活用の新潮流 - マルチモーダルAIエージェントに関する技術調査
こんにちは、AIソリューショングループの大沢直史です。
2024年までは生成AIの活用手法として「RAG(Retrieval-Augmented Generation)」に注目が集まり、多くの企業がドキュメントを対象としたRAGによる課題解決に取り組んできました。2025年は「AIエージェント元年」と呼ばれ、AIエージェントの活用が新たな注目トピックとなっています。どのようなユースケースでAIエージェントが活用できるのか、日々多くのサービスや論文が登場しています。
今後、企業におけるAIエージェントの導入が加速する中で、ドキュメント資産だけでなくeラーニングや動画教材、社内研修映像などの動画コンテンツをいかに活用するかが重要なテーマとなります。ただし、従来のRAGはテキストドキュメントを前提としており、動画を同じ仕組みで扱うことは困難です。動画には動画特有の処理や構造化のアプローチが必要であり、そのための技術活用はまだ発展途上にあります。
そこで今回は動画コンテンツをAIエージェントで活用するための最新技術について調査したためご紹介します。
RAGについての仕組みや業務への活用例を確認したい方は以下をご参照ください。

VideoRAG: Retrieval-Augmented Generation over Video Corpus
初めに、RAGを動画コンテンツに拡張した手法の紹介です。論文はこちらです。
従来RAG(Retrieval-Augmented Generation)は主にテキストドキュメントを対象に発展してきた手法であり、企業が持つ膨大なドキュメント資産をLLMと組み合わせて活用するアプローチとして注目されてきました。その一方で、動画は単なる文字情報ではなく視覚・音声・時間軸といった複雑な情報を含んでおり、従来のRAGの仕組みではその情報を十分に活用できなかったため、RAGの対象としては十分に扱われてきませんでした。
VideoRAGは、この課題に取り組んだ初期の研究の1つで、動画というマルチモーダルなコンテンツに対しても関連情報の検索・取得・生成というRAGの思想を拡張して適用することを目指しています。

研究の背景と課題
- 従来のRAGはテキストコンテンツを主としており、またマルチモーダルRAGでは画像の認識を組み込んだ処理アプローチは存在していましたが、生成AIに参照させる情報ソースとして動画コンテンツを活用する動きは限定的で、十分に考慮されていないという課題があります。
- 動画コンテンツを扱う手法として、動画をフレーム単位で分割しLLMによってそのフレームの描写をテキストに変換することで言語化して扱う手法も存在しますが、この方法では視覚的情報や時系列が失われたりと動画本来が持つ豊かなマルチモーダル情報が失われるため、動画コンテンツの操作として不十分であると著者は指摘しています。
- これまでの手法では、あらかじめ決められた動画に基づいて回答を生成するアプローチが主流でした。これではクエリに関連する動画を動的に取得する、まさにRAGの要素が実現できないという課題があります。
提案手法
- この論文ではLarge Video Language Models(LVLM)を使用したVideoRAGという手法を提案しています。LVLM(Large Video Language Model)とは、従来の言語モデル(LLM)に動画(映像+音声)理解の能力を統合したもので、マルチモーダルな入力に対して自然言語による出力を生成できるAIモデルです。
- アプローチはシンプルで、LVLMによって動画コンテンツをベクトル化するというものです。ユーザーからの質問回答は、質問の内容と動画の情報を基に行います。
- 提案手法では、すべてのフレームを処理するのは計算コスト的に非現実的であるという動画コンテンツ特有の問題に対し、回答生成に特に有用な動画フレームを抽出する動画フレーム選択機構を提案し、LVLMのコンテキスト制限に対応しています。
- 字幕のない動画に対しては音声認識を利用した補助テキスト生成を行い、映像とテキストの両方を活用したRAGを実現します。
- 論文中ではLVLMモデルとして、LLaVA-Video, InternVL, Qwen, InternVideo2を検討し実験を行っています。
VideoRAGによる回答生成
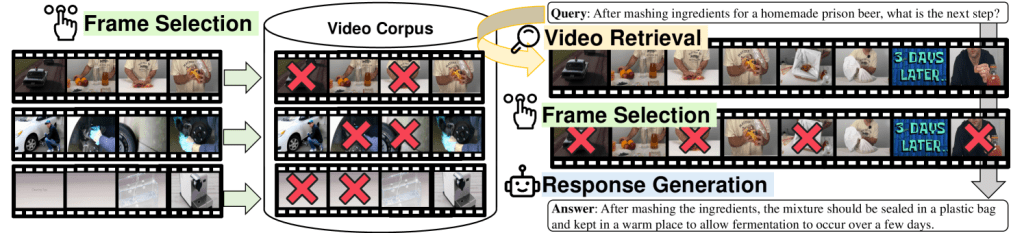
回答生成時のキーとなるアプローチを紹介します。
- Video Retrieval : ユーザークエリとVideo Corpusが持つ動画の類似度を計算し、関連性の高いtop-k件の動画を検索・取得します。
- Frame Selection : フレーム選択機構によって回答生成に必要なフレームを取捨選択します。
- Response Generation : 取得した動画情報・テキストとユーザーからのクエリをLVLMに入力し、回答を生成します。
論文の後半に、実際の実験によって行った質問とその回答が示されています。「Explain how to bake cookies on your car dashboard.」のような通常のRAGアプローチでは回答できそうにもない質問に対して適切に回答できています。
RAGとの違い
以下に簡単にRAGとVideoRAGの手法の違いをまとめてみました。比較してみると通常のテキストRAGと同様の思想に基づいて動画を扱っているだけであり、動画コンテンツを扱うハードルが下がって見えます。
通常のRAG
| ステップ | 内容 |
|---|---|
| ① ドキュメント準備 | テキストをチャンクに分割し、それぞれを埋め込み(ベクトル)化 |
| ② ベクトルDB構築 | ベクトルを格納し、クエリに応じて類似文書を検索できるようにする |
| ③ 検索(retrieval) | クエリをベクトル化し、ベクトルDBから類似度の高いチャンクを取得 |
| ④ 生成(generation) | 取得した文書+クエリをLLMに渡し、応答を生成 |
VideoRAG
| ステップ | 内容 |
|---|---|
| ① 動画準備 | 動画をフレーム+字幕に分解し、フレーム選定・特徴抽出(埋め込み生成) |
| ② ベクトルDB構築 | 各動画のベクトル表現(視覚+テキスト特徴)を格納 |
| ③ 検索(retrieval) | クエリをテキストからベクトル化し、動画の埋め込みと比較して類似動画を取得 |
| ④ 生成(generation) | 取得した動画の一部フレーム+字幕+クエリをLVLMに渡し、マルチモーダル応答生成 |
まとめ
この論文は動画をマルチモーダルのコンテンツとしてRAGに拡張した初の試みです。LVLMを使用することで、シンプルな構成ながら有効的な情報抽出を可能としています。この論文で重要な点は、複数の動画を扱うRAGを可能としているという点です。
VideoAgent: A Memory-augmented Multimodal Agent for Video Understanding
次に動画コンテンツを扱うAIエージェントによる回答生成手法を紹介します。論文はこちらです。この論文はコンピュータ・ビジョン分野のトップカンファレンスの1つであるECCV2024に採択された論文です。
研究の背景と課題
- VideoRAGと同様に動画の解釈に対する難しさを挙げています。動画コンテンツの多様なイベント、複雑な空間・時間的な関係の解釈に対する課題や、これまでの動画コンテンツに対するアプローチでは計算コストやメモリ消費が十分でなく、長尺の動画を解釈させることが難しいといった課題を挙げています。
- またAIエージェントの手法においても、動画のような長く複雑なマルチモーダル情報に対する拡張が議論されていない点や、AIエージェントがツールを通じて動画コンテンツを適切に扱う方法が無いという課題があります。
提案手法

- 論文では、動画コンテンツの管理手法として統一メモリ構造を提案し、長尺動画に対して構造的で圧縮されたメモリ表現を設計する手法を検討しています。統一メモリ構造を使用することで、時間的情報と動画に映る対象物の情報の両方を包括的に保持することができるようになります。統一メモリ構造は以下の2つのメモリによって構成されます。
- Temporal Memory (時間的メモリ):動画を短いセグメントに分割し、それぞれで何が起こっているかをテキストとして保持
- Caption:各2秒の動画セグメントに対して生成された自然言語の説明文(例:"#O The man Y pushes a stroller on the road")
- Textual Feature:Captionのベクトル表現
- Visual Feature:動画セグメントのベクトル表現
- Object Memory (対象物メモリ):動画中のオブジェクトの出現タイミング・位置・特徴を保持
- SQL Database:オブジェクトのID、カテゴリ、出現セグメントを格納し、構造化検索を可能にするデータベース
- Feature Table:オブジェクトごとの埋め込み特徴量を格納し、自然言語による検索を可能にするテーブル
- Temporal Memory (時間的メモリ):動画を短いセグメントに分割し、それぞれで何が起こっているかをテキストとして保持
- またVideoAgentは4つのToolを利用し統一メモリ構造にアクセスし、様々なクエリに対応する情報を取得します。
- caption_retrieval(キャプション取得):動画セグメントのテキストキャプションを取得
- segment_localization(セグメント検索):自然言語のクエリから、該当する動画セグメントを検索
- visual_question_answering(視覚的質問応答):特定の動画セグメントに対して直接質問をして回答を生成
- object_memory_querying(対象物メモリ検索):動画中の物体や人物の出現・状態をクエリベースで調査
まとめ
この論文は、動画をメモリ構造によって管理し、エージェントのTool利用を通じて単一の動画に対しての詳細な理解を可能とするというものでした。VideoRAGは複数の動画から情報を統合して獲得するという点で、活用可能なユースケースに違いがありそうです。
ビジネス活用を考える
VideoRAGとVideoAgentの両手法のビジネス現場への応用を検討してみます。
VideoRAGは複数の動画を横断的に解釈し回答生成ができる点がポイントでした。以下のような、類似するケースの検索や比較を行うようなケースで本手法が有効と考えます。
- 【公共・行政】災害時の行動記録検索:避難訓練や過去の災害対応動画から「避難所開設の流れ」「消防隊の動き」などを横断検索
- 【教育】講義検索:数多くあるオンライン授業動画から特定のトピックに対する検索・抽出
- 【製造】作業分析・行程チェック:複数の現場の動画を参照し、「同じ作業はどうやっているか」を検索比較し
- 【メディア】映像素材検索:数千本の素材映像から、「青空の風景」「犬が走るシーン」などを自然言語で検索
VideoAgentは1つの動画に対しての詳細な情報抽出が可能で、業務やプロセス理解といったユースケースに本手法が有効ではないかと考えます。
- 【メディア】映像のあらすじ、名シーン抽出:ドラマや映画の動画をセグメント単位で理解し、「起承転結」構造やキャラの動線を抽出
- 【製造】熟練工の作業を教材化:ベテランやプロの作業を解釈し、新人の教育材料として活用
- 【製造】作業手順の分析・検証:対象者の動作の追跡や工程ステップのキャプション化を行い「作業手順は正しいか?」「工具は正しく使っているか?」などをQA
上記以外にも、様々なユースケースが検討できそうです。
まとめ
本コラムでは、動画コンテンツを対象としたAIエージェント技術である「VideoRAG」と「VideoAgent」についてご紹介しました。これらの技術は、動画の理解と活用の可能性を大きく広げるものであり、企業が保有する動画資産の新たな活用方法として重要な役割を果たすと考えられます。
特に生成AIに参照させる「情報ソース」として動画を活用できるようになることは、従来テキスト中心だったRAG(Retrieval-Augmented Generation)の枠組みを超えるものであり、社内に蓄積された膨大な動画(会議録画、研修資料、現場映像など)が再利用可能なナレッジへと変わる可能性を示しています。
ビジネス的なメリットとしては、教育やオンボーディングの効率化・問い合わせ対応の自動化・業務ノウハウの共有等様々なメリットがあり、技術的には、マルチモーダルな大規模言語モデルの発展により、より長時間・高解像度の動画解析や、高精度な文脈理解の実現が期待されます。
今後もAITCは生成AIに関して積極的に製品開発・技術支援をしていきます。
ご相談を希望される方は、お気軽にこちらのお問い合わせフォームからご連絡ください。
筆者
AIソリューショングループ
大沢直史

