モデルオーバーハングを越えて、生成AIを業務価値に変える

目次
生成AIを業務価値に変えるピースとは
生成AIの進化は、2025年に一気に加速しました。要約、翻訳、業務分析、資料作成、画像認識、コード生成。生成AIを様々なユースケースで活用した事例を見るたびに「ここまでできるのか」と驚かされます。
一方で、現場の感触はどうでしょう。
・便利だけど、結局は“調べ物”止まり
・大事な業務ほど怖くて入れられない
・データや権限、監査の話が出ると前に進まない
このギャップを説明する言葉として、最近よく使われるのが「モデルオーバーハング(model overhang)」です。モデルの能力が先行して伸びるのに、業務で価値へ変換する仕組みが追いつかない。結果として、モデルの力が“実世界の成果”に変換されない状態が生まれます。
言い換えるなら、生成AIが賢くなったこと自体は疑いようがないのに、業務側がまだその賢さを受け止める形になっていない。これがモデルオーバーハングの正体です。
ちなみに、同じような背景を表す言葉として、能力オーバーハング(capability overhang)という言葉もあります。使い手や組織の側が”能力”を活かし切れていない状況を表す言葉で、同じようなコンテクストで使われます。
モデルオーバーハングはなぜ起きるのか
モデルオーバーハングは、モデルの精度不足というより、業務が「出力」ではなく「手続き」と「責任」で動いていることに起因します。
生成AIが、業務に関する質問に対して、それっぽい答えを返すだけなら成立します。ですが、業務はそこで終わりません。次の壁が必ず出てきます。
1.データが繋がらない:部門別に分断、参照先選択が人任せ
2.権限が整理できない:誰が何を見られるか、権限や監査要件に耐えない
3.例外が扱えない:イレギュラー時の分岐・差し戻し・承認が設計されていない
4.品質が運用できない:評価(Evals)、ログ、改善のループが回らない
つまり、モデルが賢くなっても、業務の中で“動ける形”になっていない。ここに本質があります。
モデルの進化に、業務システムが追いつかない典型パターン
私がよく見る典型パターンは、次の流れです。
第一段階:社内利用の試行
生成AIを業務に適用し、便利さを実感する。問い合わせ対応や要約などの小さな改善が進む。
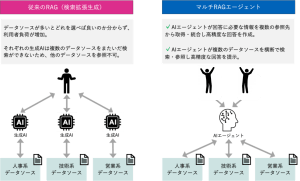
第二段階:RAGで社内知識を扱えるようになる
規程、マニュアル、議事録、FAQなどが自然言語で引けるようになり、“検索”が変わる。
第三段階:運用が進むほど、課題が表面化する
- RAGが増えて「どれに聞けばよいかわからない」
- 情報源が部署ごとに散って「横断の答えが出ない」
- 権限や監査で「業務に入れられない」
- 業務要件に対してモデル選択が固定化されることで「この業務には合わない」が増える
便利さを超えて、中核業務に適用しようとした瞬間に、モデルオーバーハングが顔を出します。
ここで必要なのは、より賢いモデルを待つことではありません。モデルの力を業務成果に変換する“システム化”です。
もう一つの見落としがちな要因:業務ごとに最適な生成AIを選べていない
ここで、もう一つ重要な観点があります。生成AIを業務で活用しようとするとき、現場では往々にして「まずはこのモデルで全部やる」という発想になりがちです。しかし実際には、業務によって求められる要件がまったく異なります。
たとえば、同じ“生成AI活用”でも、必要なのは以下のように別物です。
・規程や契約のレビュー:根拠提示、慎重な推論、監査への耐性
・技術文書の検索と要約:長文コンテキスト、引用の確実性、検索の精度
・問い合わせ対応:速度、コスト、定型対応の安定性
・設計支援やコーディング:プログラミングスキル、ツール実行、手順化、反復作業の強さ
・社内ナレッジの横断分析:複数データソースの統合、推論の整合性
このとき重要になるのが、業務ごとに「精度」「速度」「コスト」「コンテキスト長」「安全性」「ツール連携」「プログラミングスキル」などの観点で、最適な生成AIを選び、使い分けられることです。モデル選定が固定化されると、どこかの業務で必ず無理が出ます。その無理が、運用上の例外や品質問題として顕在化し、結果的に“使われない”方向へ戻ってしまう。これもモデルオーバーハングを拡大させる典型要因です。
要するに、生成AI活用は「モデルを導入する」ではなく、「業務要件に合わせてモデルを編成する」ことも大切になります。
それでは、このモデルオーバーハングをどう解消するか?
では、何から手を付けるべきか。現場で効きやすい打ち手を、私なりに整理します。
- ターゲット業務を選定する
- 生成AIを入れる業務を絞り、入力→判断→実行→承認までの流れを最初から設計します。全部やるのではなく、価値が出る一点から始めるのが現実的です。
- RAGを“使える形”にする
- 文書を繋ぐだけでは足りません。必要なのは、誰でも迷わず使える導線と、どの情報源を当たるべきかをAI側が吸収してくれる設計です。
- 権限・監査を後付けしない
- 企業利用は、最後に必ずここに戻ってきます。認証、アクセス制御、監査ログ、説明責任。最初から組み込み、運用できる状態にしておくことが重要です。
- 例外処理とHuman-in-the-loopを設計する
- “最後は人が責任を持てる”線引きが必要です。差し戻し、承認、根拠提示。AIが自動で進める部分と、人が判断する部分を最初から決めます。
- 評価と改善のループを作る
- 業務に入れた瞬間から、品質は運用課題になります。利用ログを見て、どこで詰まり、どこで誤るかを把握し、改善していく仕組みが不可欠です。
- 業務ごとに最適な生成AIを選び、切り替えられる設計にする
- 全業務を単一モデルで実行する発想を捨てます。業務要件に応じて、モデルを選択・切替できる構造を持つことで、精度・コスト・スピード・安全性のバランスが取りやすくなり、運用の無理が減ります。例えば、Gemini 3 Proの精度が良さそうという理由だけで画像認識と文書検索を同じモデルで行うのではなく、実際にそれぞれのプロセスで使う生成AIを使い分けた方が、より良い精度を得ることが出来る場合が多いです。ここが、実は“定着率”に直結します。
ポイントは一貫しています。チャット導入で終わらせず、”業務に耐えるシステム”を最初から想定し、そのゴールに向かって進めること。これがモデルオーバーハングを越えるための現実的な道筋です。これは、ウォーターフォールで進めようと行っているわけではありません、アジャイルに進めるとしても、です。
“答えるAI”から、“つなぐAI”へ
モデルオーバーハングを越えるために必要なのは、より賢いモデルを待つことではありません。業務の中で生成AIが「使える」状態に落とし込むことです。言い換えるなら、モデルの能力を、業務価値へ確実に変換できるシステムにすることです。
そのためには、業務ごとに求められる精度・速度・コスト・安全性を見極め、最適な生成AIを選び分けられることが前提になります。同時に、増え続ける社内データやRAGを“どれに聞けばよいか”で迷わせず、必要に応じて横断し、統合して答えられる「つなぎ方」が欠かせません。
そして何より、企業の業務は責任と手続きで動いています。権限管理、監査ログ、例外処理、承認線、評価と改善の運用、これらを後から付け足すのではなく、最初から組み込んでおかない限り、生成AIは中核業務へ入っていけません。モデルオーバーハングの正体は、まさにこの“システム化・運用化の不足”にあります。
そして、ここまでの「このモデルオーバーハングをどう解消するか?」を実現するソリューションが、権限・監査を後付けしないKnow NarratorやKnow Narrator AgentSourcingのマルチRAGエージェントです。

筆者
AITC センター長
深谷 勇次

