ChatGPTで社内文章を活用するには学習は必要?RAGについてわかりやすく解説!
こんにちは。AITCのデータサイエンティストとして、お客様の業務にChatGPTをはじめとする生成AI導入プロジェクトを支援させていただいてる徳原光です。
OpenAI社のChatGPTは2022年にGPT-3.5が発表されて以来急速にビジネスに普及しました。GeminiやClaudeといったモデルが登場した現在でもGPT-4.1やGPT-o1、o3、o4モデルなど最新のOpenAI社のモデルが日本企業のビジネスの現場で使われ続けていますし、プライベートの利用でも無料で使える生成AIChatGPTは一番身近で信頼できる生成AIサービスとして2025年現在でも支持を集めています。
AITCが支援しているお客様でも、弊社ソリューションKnow Narratorを用いたChatGPT導入事例が公開されています。

そこで、より注目されるようになったのが、ChatGPTによる社内文書活用です。
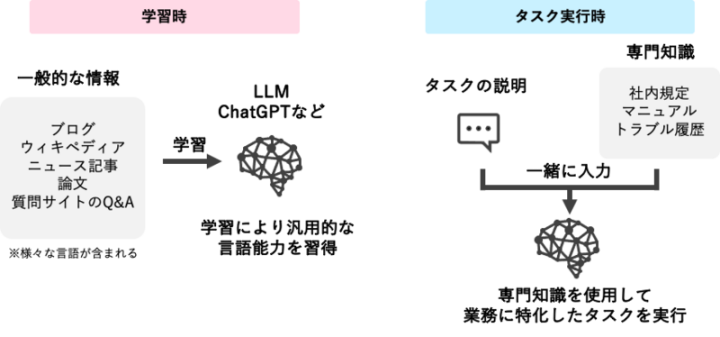
ChatGPTは膨大な情報を学習していますが、覚えている情報は一般常識であったり汎用的な内容に限定されています。しかし、様々な業務でChatGPTを活用するために、製品の仕様書や社内規定、業務マニュアルといった社内文書に含まれる専門知識をChatGPTに認識させたいと感じる方も多いのではないでしょうか。
現在、ChatGPTによる社内文書活用手法で最も有力だと考えられている方法はRetrieval-Augmented Generation(RAG)という手法です。
この記事では本サイトでも何度も取り上げているRAGについて、その仕組みや、活用方法、ファインチューニング(転移学習・既存のAIモデルに再学習によって新たな知識を覚えさせる手法)とは何が違うのか、わかりやすく解説したいと思います。企業内に大量に存在する社内文書の生成AIによる利活用にお役立てていただければと思います。
Retrieval-Augmented Generation:RAGとは?
「AIに情報を覚え込ませるには、一度データをAIモデルに学習させないといけない」という認識がこれまでのAI界の常識であったと思います。
皆さんもそういった認識が強いのではないでしょうか?
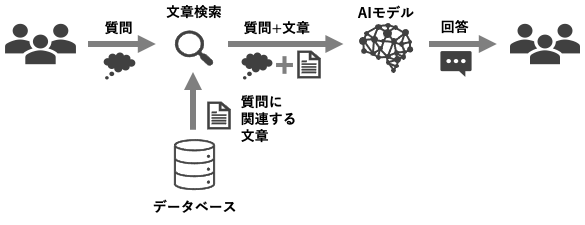
しかし、RAGでは学習とは違う方法でAIに新しい情報を認識させます。それはタスクを実施する度に必要な情報を毎回渡す手法です。
もちろん、AIモデルの構築には学習は必要です。しかしRAGで使用するモデルには、webから集めた膨大な一般知識を学習させるものの、実行したいタスク固有の専門知識は学習させません。
タスクの実行時では回答を得るために必要な情報を参照文書から抽出し、質問文と共に指示文(プロンプト)としてAIに入力することで、AIにタスク固有の知識を認識させるというのがRAGの基本的な考え方になります。
実は、RAGの考え方は2020年にGoogle社の研究者から発表されたもので、ChatGPTが登場する前から存在しましたが、現在生成AIとして普及しているChatGPTを含むLLM(大規模言語モデル)が次々と開発されたことで、より注目されるようになりました。
理由は、LLMがこれまでのAIモデルと比較して圧倒的に高い言語認識能力を有しており、加えて様々なタスクに対して臨機応変に対応する事ができるという特徴にあります。
これにより、専門知識を学習させてタスクに特化したAIモデルと開発するよりも、RAGの考え方を適用して既に学習済みのChatGPTといったLLMのモデルに特定のタスクに必要な情報を入力し、個別タスクを実施させたほうが、性能が向上しやすい結果が得られました。
もちろん、RAGでは知識を実行毎に入力する必要があるので、入力文章量が増えてしまうというデメリットがあります。しかし、ChatGPTは一度に入力できる情報が多いため、多くの情報が必要な場合でも知識をすべて入力することができます。
また、一度に入力する情報量も検索システムを用いて情報を厳選することで抑えることが可能になりました。この仕組みをソリューション化したのが弊社が開発したKnow Narrator Searchになります。
GPTモデルのファインチューニング(転移学習)は可能なのか?
LLMにとってRAGが有効であるとは言え、業務固有の専門知識をAIモデルにファインチューニングで学習させることも選択肢の一つとして挙がります。
現在、OpenAI社のChatGPTサービスとMicrosoft社が提供するAzure OpeanAI ServiceではGPT-4.1といった既存のChatGPTのモデルをファインチューニングして性能を向上させる機能がすでに提供されています。

また、オープンソースとして公開されているLLMのモデルに自前の学習環境で新たな知識を学習させることも可能です。
身近な選択肢となったファインチューニングですが、いくつかデメリットも存在します。
まず、学習コストが非常に高いことです。ChatGPTは膨大な知識を取得するために非常に大きなモデルになっています。このモデルに新たな知識を会得させるには、莫大な計算が必要となり、現在公表されているファインチューニングの費用は高額なものになっています。
他のLLMモデルも同様に、既存のAIモデルと比較すると学習コストが軒並み高額になります。
また、ファインチューニングを実施した事例が少なく、どのくらいデータをどの程度学習させれば効果が出るのか、知見が少ないというのもデメリットの一つかもしれません。
また、RAGの場合はタスクの実行時に専門知識から必要な情報を検索システムなどにより厳選して入力するようにしておけば、膨大な情報をタスクの内容に合わせて活用できます。しかし、ファインチューニングでは、使う可能性がある情報はすべて学習時に覚え込ませないといけないため、情報が増えるとその分学習コストが増加します。
さらに、GPT-3.5、GPT-4.0、GPT-4o、GPT-4.5、GPT-4.1そして、推論モデルであるGPT-o1、GPT-o3等次々の発表されるChatGPTの最新モデルを使用するには、新しいモデルが出るたびにファインチューニングを実施してモデル自体に情報を覚えさせる必要がありますが、RAGなら使用するモデルを入れ替えるだけで簡単に最新のモデルを使うことができます。
様々課題に対処する必要があるファインチューニングですが、高額な費用をかけてモデルを学習したのに成果が得られないリスクを考えると、まずはRAGによる文章活用を検討するのが今のところは定石だと言えます。
ChatGPTによる社内文書活用プロジェクトの進め方
最後に、これまでAITCで実施してきたKnow Narrator Searchの事例を踏まえて、社内文書を利用してChatGPTに業務に特化したタスクを実施するための方針を整理します。
RAGを用いるかファインチューニングを用いるか検討する前に、まずはChatGPTに実施させたいタスクの内容を整理し、アウトプットを具体化させます。
例えば、製品マニュアルから情報を得て、製品の仕様に関する質問に答えるのであれば、具体的にどの製品の、どのマニュアルから情報を得て、どのような形式、具体性、正確性で回答するのか定義します。この時、具体的な回答例を参照文章も含めて数件挙げておくといいかもしれません。
次に使用できる社内文書を整理します。この時、何らかのシステム上に情報が存在しているのであれば、情報を出力する方法かシステムとChatGPTを連携する方法を検討してください。
情報の保存形式も重要でExcelファイルのような表形式で情報が保存されている場合はChatGPTは表形式の情報を認識するのが苦手なので、同じ情報が別の形式で存在しないか検討します。
もし表形式のデータにしかない場合は、2次元のデータをJson形式の様なAIモデルが理解し易い形式に変換するかそれに準ずる形式に変換することが有効です。
最後に活用したい情報の量と、タスクの実施頻度を整理して、ChatGPTに与える情報が適切かどうかを判断し、参照文章を調整します。もし情報が不足している場合は、新たにデータを追加する必要がありますし、多すぎる場合は回答精度が落ちますので、使用頻度が少ない文章をデータベースから除外したり、利用目的によってデータベースを分けることも検討します。
こちらに、具体的なRAGの精度改善方法がまとめられてますので、ぜひ参照ください。

RAGで期待した回答が得られない場合、ファインチューニングによる専門知識の学習を検討することになりますが、今後ChatGPTによる文章活用事例が増えてくることで、専門知識といった重要知識はファインチューニングで学習し、製品の仕様といった細かい知識はRAGで対応するなどのハイブリッドな手法をとる事例が増えてくる可能性もあります。
ChatGPTを含むLLMは現在新たなモデルが次々に発表されています。それぞれのユースケースやコストの観点で、ベストプラクティスと思われる手法は変化する可能性があります。
AITCが開発したKnow Narrator Searchを導入することで、RAGによる社内文章活用環境を高精度かつセキュリティを担保した状態で構築することができますので、ぜひご検討ください。精度改善などのサポートも実施します。現在RAGを無料で利用できるサービス等も増えてきていますが、セキュリティや回答精度の観点で業務で使用する場合は弊社のKnow Narrator Searchのようなエンタープライズ向けのサービスを利用することをお勧めします。

詳しくはこちらのページを御覧ください。
ChatGPTによる社内文書活用にお困りの方はお気軽にAITCにご相談ください
本コラムでは、ChatGPTによる社内文章活用についての知見をまとめさせていただきました。
次の記事ではRAGによって業務効率化を実現するために考えるべきポイントを解説します

今後もAITCではChatGPTを用いたソリューション開発や、研究開発を推進して参りますので、ChatGPTや生成AIをビジネスに活用したいと思われている方は、ぜひお問い合わせいただいて、直接ディスカッションさせていただければと思います。
ご相談を希望される方は、お気軽にこちらのお問い合わせフォームからご連絡ください。

筆者
AIコンサルティンググループ
徳原光

