生成AIエージェントのワークフローの実装方法と関連ライブラリについて理解する

目次
はじめに
2024年、Google I/O、OpenAI Spring Update、Microsoft Buildといった生成AI界隈で重要なイベントが実施されました。
各社の発表の中で目立ち始めたのが「AIエージェント」というキーワードです。すでにアカデミアや海外ベンチャーではAIエージェントが盛り上がっています。国内でも最近エージェントに関する話題を耳にすることが増えました。しかし、実装方法の解説記事などは少なく、どのような実装選択肢があるか悩む方も多いのではないでしょうか。
そこで、本記事ではエージェントもしくはAgentic workflowと呼ばれる生成AIの運用プロセスの実装に関して、Pythonを使用した場合のメジャーな実装選択肢と実装方法について紹介します。
本記事を通してエージェントの実装について知見を得ていただけたら幸いです。
※ 本記事ではLLMの使用環境として、Azure OpenAI ServicesのAPIを利用します
エージェントとは
本記事でのエージェントとは、GPTに代表される大規模言語モデル(LLM)を使用し、目標を達成するために自律的に機能するシステムのことを指します。エージェントは環境を認識し、問題を解決し、目標に向かって行動することができます。このプロセスは人の直接的な指示なしに行われ、エージェントは自らの判断でタスクの実行が可能です。
AIエージェントではLLM自身がタスクの実行手順を計画し、計画に応じてタスクを実行します。この実行手順を指して一般的にはエージェントワークフローと呼びます。AIエージェントは複雑な指示に対しても作業レベルでタスクを分解しエージェントワークフローを自動的に定義し、そのフローに応じてタスクを事項するので様々な指示に対応できます。
エージェントに関しては同グループの太田さんが関連情報をまとめて提供しておりますので、ぜひ参考にしてください。
そもそもエージェントワークフローはどうやって作成するのか
エージェント的な推論パターンとして、Stanford大学の教授であり、人工知能の第一人者とも言われるAndrew先生のエージェント講義の中で、以下の4つのデザインパターンが示されています。
- リフレクション(Reflection)
- LLMの出力をLLMが見直して改善するプロセス
- ツールの使用(Tool use)
- Web検索ツールのようにLLM自身では実現できない操作を外部ツールで実現するプロセス
- プランニング(Planning)
- LLMが与えられた指示を達成するための計画を作成するプロセス
- マルチエージェント協働(Multi-agent collaboration)
- 複数のエージェントが協力・競争することで複雑なタスクを実現するもの(会話シミュレーションなど)
エージェントワークフローは様々なユースケースが考えられますが、ほとんどの場合上記のパターンを組み合わせて実現することになるでしょう。
参考:Four AI Agent Strategies That Improve GPT-4 and GPT-3.5 Performance
エージェントワークフローの実装における技術選定
ここからは実際にどのようにエージェントワークフローを構築するのか紹介します。 例として以下のエージェントワークフローの実装を考えます。こちらはQAタスクを行うエージェントを想定しています。
エージェントワークフローをQAタスクに適用した取り組みはAIエージェントは何から取り組む?社内取り組み紹介 - AITC - ISID | AI トランスフォーメンションセンター コラム でも紹介しています。
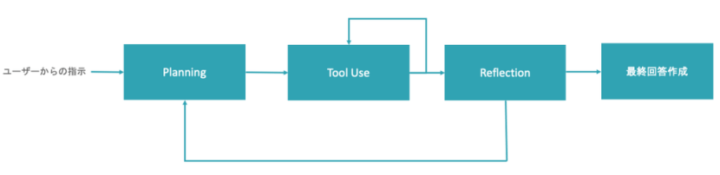
エージェントワークフローの構築に関して最近はDifyやGPTs などのローコード・ノーコードツールもありますが、今回は1からPythonでエージェントワークフローを作ることを想定し、LangGraph、LangChain、OpenAIライブラリを使用したパターンを紹介します。
LangChainやOpenAIライブラリは、特にOpenAIのAPIをPythonで利用するための主要なライブラリです。一方、LangGraphはこれら2つに比べて知名度が低いかもしれません。LangGraphとは、LLMを用いたステートフルでマルチアクターのアプリケーション(上図のようなパターン)を構築するためのライブラリです。LangGraphでは、LangChainだけでは書きづらかったLLMを繰り返し呼び出してアクションを実行するような処理を比較的簡単に実装できます。
参考:🦜🕸️LangGraph | 🦜️🔗 LangChain
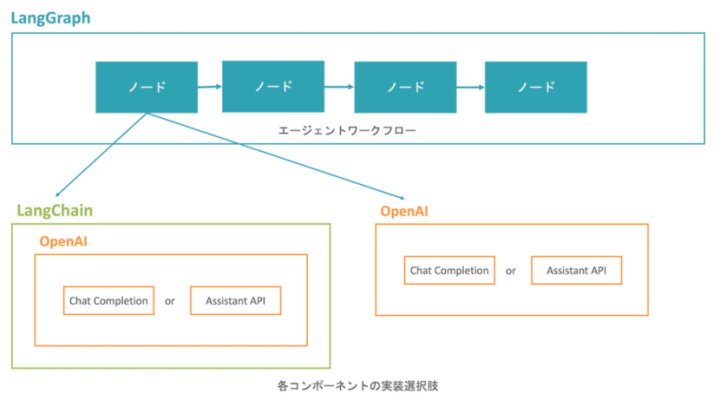
本記事では、図のようにエージェントワークフローの構築はLangGraphで行い、エージェントワークフローのノードの処理はLangChainで行うパターンを紹介しています。
詳細は割愛しますが、LangGraphとLangChainを使わないパターンも実装しており、その場合の比較が以下になります。まずはOpenAIのAPI実行部分やtool関連の実行部分でLangChainを使うパターンとLangChainを使わずにOpenAIライブラリのみを使用した場合の実装のメリデメです。
| メリット | デメリット | |
|---|---|---|
| LangChain (version=0.1.20) | ・ 生成AIとtoolを使った処理のようによくある実装に関しては簡単な方法が用意されており、コーディング時間を短くし素早く結果を得られる ・ 個人利用などでLangSmithが使える環境であれば実験管理が簡単 | ・ ライブラリのライフサイクルが早いので既存の使い方がすぐにdeprecateになる可能性がある ・ 内部の処理を理解するのに時間がかかる ・ 細かいカスタマイズ方法を探すのに時間がかかる |
| OpenAI (version=1.30.1) | ・ 生成AIを用いた処理の大元になるため細かいカスタマイズやデバッグが直感的に行える | ・ 全ての処理を自分で書く必要があるため、コード記述量が増え複雑な処理フローの構築に時間がかかる |
Tips: LangChainに馴染みがなく、そこそこ複雑なフローを試したい場合は、OpenAIから始めた方がチューニングしやすく、エージェントフローの中身の理解が深まるためおすすめです。そこからLangChainに置き換えられそうなところを置き換えていくといいと思います。
OpenAIのChat Completion APIを使うか、Assistants APIを使うかは以下の観点で選ぶと良いでしょう。こちらはあくまで検証目的での実装を想定したメリットとデメリットです。
| メリット | デメリット | |
|---|---|---|
| OpenAI Chat Completion API | ・仕組みが一番単純なため学習コストが低く、拡張性が高い | ・状態を持たないのでチャット履歴などすべてクライアント側で管理する必要がある |
| OpenAI Assistants API | ・アシスタントとクライアント間のメッセージ履歴の管理が可能 ・Code InterpreterやFile SearchといったAssistants API限定toolが利用できる | ・アシスタントやスレッド管理などChat Completionとは異なる仕組みを理解する必要がある ・スレッドを使い回すとトークン量が上限まで累積し続けるため、削除が必要 |
Assistants APIは状態を持つところが利点であるのですが、ワークフローの検証段階でプロンプトやtoolを頻繁に変える場合はChat Completion APIで十分です。
LangGraphでエージェントワークフローの構築
エージェントワークフローでは上述のように、役割の異なる要素をつなぎ合わせて最終的な結果を得ます。実際にはこの繋ぎ合わせ方が実行したい内容によって多種多様であり、循環や並列、分岐などを考慮するとそれらを柔軟に構築できる仕組みが求められます。
LangGraphでは 最初にグラフと状態を表すクラスを定義します。この状態クラスは各ノードの引数として渡され、ノードが更新を行なっていきます。記載した状態クラスは例です。
# LangGraphでエージェントのワークフローの初期化
import operator
from typing import TypedDict, List, Tuple,Annotated
from langgraph.graph import StateGraph
# ワークフロー前端の状態を記録するためのクラス
# 基本的に各ノードにこのクラスが引数に渡される
class AgentState(TypedDict):
input: str
answer: str
past_steps: Annotated[List[Tuple], operator.add] # 追加操作を行う変数
# Graph全体を定義
workflow = StateGraph(AgentState)次に定義したグラフにノードを追加します。LangGraphではエージェントワークフローの各要素をノード、ノード間のつながりをエッジとして考えます。ノードには対応する処理関数を紐づけます。エッジに条件をつけたい場合はadd_conditional_edgesと条件が書かれた関数を用意します。
# LangGraphでエージェントワークフローの構築
# 使用するNodeを追加。Node名と対応する関数を書く。名前はこの後も使うので一意である必要がある
workflow.add_node("planner", create_plan)
workflow.add_node("agent_executor", execute_action)
workflow.add_node("reflector", reflection)
workflow.add_node("answer_creator", create_answer)
# エントリーポイントを定義。これが最初に呼ばれるNode
workflow.set_entry_point("planner")
# Nodeをつなぐエッジを追加
workflow.add_edge("planner", "agent_executor")
workflow.add_edge("answer_creator", END)
# 条件付きエッジを追加。reflection処理に入るか否かを判定する
workflow.add_conditional_edges(
"agent_executor", # つなぎ元のNode
should_continue_execute_action, # 条件判定関数
{
# 結果が"continue"ならactionにつなぐ
"continue": "agent_executor",
# 結果が"end"なら終了
"end": "reflector",
},
)
# 条件付きエッジを追加。再計画か最終回答作成に移行するか否かを判定する
workflow.add_conditional_edges(
"reflector", # つなぎ元のNode
should_replan, # 条件判定関数
{
# 結果が"continue"ならactionにつなぐ
"continue": "planner",
# 結果が"end"なら終了
"end": "answer_creator",
},
)
# 最後にworkflowをコンパイルする。これでLangChainのrunnnableな形式になる
app = workflow.compile()
LangGraphの良いところは上記のようにワークフロー全体を俯瞰しやすい、状態に基づいたループ処理が書きやすい点です。LangGraphを使わずに実装した場合、Pythonのwhile、for文でループを書くことになりますが、ループが複数箇所に出てくると非常に煩雑になりデバックが困難になります。
実行するときは以下のようにすると各ノードでの実行結果を段階的に出力できます。
# エージェントのワークフローの実行
inputs = {
"input": "app serviceとstatic web siteの使い分けを教えて",
}
for s in app.stream(inputs):
print(list(s.values())[0])
print("----")
また、LangGraphでは定義したグラフ構造を画像やasciiで出力も可能です。

そのほかLangGraphでは、LangChainの機能を利用した便利なPrebuiltクラスが複数提供されています。詳細についてはドキュメントをご参照ください。
参考:Prebuilt Components - LangGraph
以降では、エージェントワークフローの各ノードでの処理についてLangChainを利用した場合を例に紹介します。なおPlanningとReflectionは、プロンプトや出力形式の違いくらいで実装方法としては変わらないのでPlanningのみを紹介します。同様に最終回答作成部分に関しても今回はシンプルに出力を生成するパターンを想定しているため割愛します。
LangChainによるPlanning実装
OpenAIライブラリを使った場合の実装方法を理解されてる方のために、下記フローのPlanning部分を実装するためのLangChainを使った便利な実装方法を紹介します。

Planningではタスクが記載されたリストを作成します。ここでの実装ポイントは出力が後ろのTool Useの入力になるため、そこで扱いやすいように決められたスキーマで出力を作成することです。 Reflectionの場合も基本的には同様でReflection結果を後ろのノードで扱いやすいオブジェクトにすることが求められます。
2023年11月からOpenAIのAPIではJSON Modeが実装され、以前よりは出力を扱うのが楽になりました。LangChainでも同様に出力を扱いやすくする方法が提供されています。LangChainの良いところは出力をPydanticのクラスとして定義できるため、型付きで変数を扱え、後続処理でハンドリングしやすくエディターの補完も効いたりと実装上便利です。
LangChainで出力をPydanticのクラスで実現する方法は、現時点でBeta機能の.with_structured_outputとDeprecate予定のcreate_structured_output_runnableの2つがあります。
使い方は以下の通りです。まずはモデルやプロンプトなどの共通部分の定義です。
# モデルとプロンプト、出力クラス定義
import os
from typing import List
from langchain_openai import AzureChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain.chains.openai_functions import create_structured_output_runnable
from langchain_core.pydantic_v1 import BaseModel, Field
eastus_deployment_name = os.environ.get("EASTUS_AZURE_OPENAI_DEPLOYMENT_NAME")
eastus_azure_endpoint = os.environ.get("EASTUS_AZURE_OPENAI_ENDPOINT")
eastus_api_key = os.environ.get("EASTUS_OPENAI_API_KEY")
api_version = os.environ.get("OPENAI_API_VERSION")
model = AzureChatOpenAI(
api_version=api_version,
deployment_name=eastus_deployment_name,
api_key=eastus_api_key,
azure_endpoint=eastus_azure_endpoint,
temperature=0,
)
# 実験用のプロンプト定義
system_prompt = """あなたはソフトウェアのカスタマーサポートに特化したアシスタントです。\
ユーザーの質問に答えるために以下の指示に従って課題解決の計画を立ててください。\
#絶対守るべき制約事項
- 全ての質問に対するサブタスクを用意すること
- サブタスクは、**具体的にどの機能やAzureリソースに対して何を知りたいのかを検索可能なクエリ形式で表現すること**
- できるだけ3ステップで計画を立てること
"""
planner_prompt = ChatPromptTemplate.from_messages(
[("system", system_prompt), ("human", "{input}")]
)
# 出力するPydanticクラス
class Plan(BaseModel):
"""plan for task execution"""
steps: List[str] = Field(description="steps for task execution")
内部的にはOpenAIのtoolsを使用しているため出力となるPydanticクラスにはクラスのdescriptionと変数のdescriptionを書いてください。
こちらが本題のcreate_structured_output_runnable の場合の書き方です。
# 出力クラス、model、プロンプトを渡す
planner = create_structured_output_runnable(Plan, model, planner_prompt)
plan = planner.invoke({"input": "app serviceとstatic web siteの使い分けを教えて"})
# 結果
# plan.steps=['Azure App Service の機能と利点を検索', 'Azure Static Web Apps の機能と利点を検索', 'App Service と Static Web Apps の使い分けに関するガイドラインを検索']出力結果のplan変数みると、Pydanticのクラスになっており、定義した変数名と型通りの結果が格納されていることが分かります。
続いて.with_structured_output のパターンです。プロンプトやモデル、出力クラス定義は上記と同様です。
structured_llm = model.with_structured_output(Plan)
chain = planner_prompt | structured_llm
plan = chain.invoke({"input": "app serviceとstatic web siteの使い分けを教えて"})
# 結果
# plan.steps=['Azure App Service の機能と利点を検索', 'Azure Static Web Apps の機能と利点を検索', 'App Service と Static Web Apps の使い分けに関するガイドラインを検索']結果はどちらも同じになります。新しい方がimportが少なく済むので使いやすいです。内部的にはデフォルトではどちらもOpenAIのtoolsの仕組みを利用してPydanticモデルを出力します。
またどちらの手法もOpenAIのjsonモードに対応するパラメータが用意されています。ただしその場合はプロンプトにjsonで出力するようにという指示を加える必要があります。
出力整形だけが目的であればPydanticのクラス定義を用いた上記の方法がおすすめです。
LangChainによるTool Use実装
エージェントワークフローにおいてコード量が増える要因としてTool実行部分が挙げられます。LangChainではAgentExecutorというTool実行を簡単に行うクラスが活用できます。
OpenAIライブラリを用いた実装の場合、以下のようなtool定義を含めてリクエストし、レスポンスのtool_callsの内容をもとに手元でtoolを実行、toolの実行結果を含めて再度送信する流れになります。詳しい実装はAzureのこちらをご覧ください。
参考:Azure OpenAI Service で関数呼び出しを使用する方法 - Azure OpenAI Service
{
...,
"tools": [
{
"type": "function",
"function": {
"name": "search_microsoft_learn_docs",
"description": "Microsoft Learnのコンテンツ検索できる",
"parameters": {
"type": "object",
"properties": {
"keywords": {
"type": "string",
"description": "search keywords in English"
}
},
"required": ["keywords"]
}
}
}
],
...
}愚直に書くとかなりコード量が増えますが、LangChain準拠のtool定義とAgentExecutorを使うことで以下のように簡潔になります。
まずtool作成部分です。こちらはMS Learnを検索してくる想定のtoolになります。
# LangChain準拠のカスタムtool作成
from typing import List, TypedDict
import requests
from langchain.pydantic_v1 import BaseModel, Field
from langchain.tools import tool
class SearchResponse(TypedDict):
sentence: str
datePublished: str
class SearchInput(BaseModel):
keywords: str = Field(description="search keywords in English")
@tool("search_microsoft_learn_docs", args_schema=SearchInput)
def search_microsoft_learn_docs(keywords: str) -> List[SearchResponse]:
"""Microsoft Learnのコンテンツ検索できる"""
# 検索APIのURL
url = "https://example.com/api/web-search"
# APIに送るデータ(GETリクエストの場合は不要、POSTリクエストの場合はこの部分を使用)
data = {
"keywords": keywords,
}
# POSTリクエストを送信する場合
response = requests.post(url, json=data)
# 200以外はエラーとして扱う
response.raise_for_status()
return [
{
"sentence": res["sentence"],
"datePublished": res["datePublished"],
}
for res in response.json()
]上記のOpenAI準拠のtoolの内容と合うように関数のdescription、引数のdescriptionを記載できるようになっています。
LangChainのAgentExecutorでtoolを使用する際は基本的に上記の形式で定義されたtoolを渡すだけで、内部的にOpenAI形式に変換して使ってくれます。
Tips: 変数名や関数名がtool選択に影響するため処理にあった命名を行う必要があります
以下がカスタムツールを使用した場合のAgentExecutorのコードです。
# LangChainのAgentExecutorを利用したTool Use処理
import os
from langchain_openai import AzureChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, PromptTemplate, HumanMessagePromptTemplate, MessagesPlaceholder
from langchain.agents import AgentExecutor, create_tool_calling_agent
from langchain.callbacks import get_openai_callback
from src.tools.ms_learn import search_microsoft_learn_docs
eastus_deployment_name = os.environ.get("EASTUS_AZURE_OPENAI_DEPLOYMENT_NAME")
eastus_azure_endpoint = os.environ.get("EASTUS_AZURE_OPENAI_ENDPOINT")
eastus_api_key = os.environ.get("EASTUS_OPENAI_API_KEY")
api_version = os.environ.get("OPENAI_API_VERSION")
model = AzureChatOpenAI(
api_version=api_version,
deployment_name=eastus_deployment_name,
api_key=eastus_api_key,
azure_endpoint=eastus_azure_endpoint,
temperature=0,
verbose=True,
)
prompt = ChatPromptTemplate.from_messages(
[
HumanMessagePromptTemplate(
prompt=PromptTemplate(
input_variables=["input"],
template="{input}",
)
),
MessagesPlaceholder(variable_name="chat_history", optional=True),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
tools = [search_microsoft_learn_docs]
# Construct the OpenAI Tools agent
agent_runnable = create_tool_calling_agent(model, tools, prompt)
agent_executor = AgentExecutor(
agent=agent_runnable,
tools=tools,
verbose=True,
return_intermediate_steps=True,
stream_runnable=False,
)
with get_openai_callback() as cb:
result = agent_executor.invoke(
{
"input": "app serviceとstatic web siteの使い分けを教えて",
}
)
print(cb)AgentExecutorでは、内部的にOpenAIのレスポンスからtool呼び出しに必要な情報を抜き出し、toolの実行結果の取得、実行結果のOpenAIの送信までを全てやってくれます。
今回の例ですと、クエリに調査事項が2つ含まれていますが、複数toolの呼び出しにも対応してるので一度の実行で関数呼び出し用クエリを2つ分生成し、それぞれ関数で実行して結果を取得、結果を含めた回答の生成までを行います。
それぞれでエージェントワークフローを組んでみて
それぞれの目的や環境に応じて使い分けるという前提にはなりますが、特に制約がなければLangGraphでフローを組む、フローの中のノード処理は一旦シンプルなOpenAIライブラリを使う、ある程度全体のフローや処理内容が固まったら置換可能な箇所をLangChainで置き換えていくのが得策だと考えています。
LangChainはコードの記述量が少なく、素早く実装できますが、LangChainにあまり馴染みがない場合、中身の処理を追うのが比較的難しいです。したがって、OpenAIライブラリを使えば簡単に実装イメージがつく処理も、LangChainでどのように実現するのかを調査・理解するのに時間がかかります。
実際、自分たちで実装を行った際も、エージェントワークフローの試行錯誤はLangChainを使わない方が早かったです。個人のコーディング力にもよりますが、単純にLangChainの調査に時間を使わず、すぐに新しいやり方を試せるのが大きな利点です。
LangGraphに関しては、ワークフローを組むだけであれば学習コストがそれほど高くなく、改善もしやすいので最初から使うと良いでしょう。逆にLangGraphを使わずに書いてしまうと、ループや条件分岐が増えてデバッグがしづらくなります。
また最初から使うと良さそうなLangChainの要素としてはPydanticを使用した出力整形とTool定義です。どちらもOpenAIの仕様を理解していれば比較的簡単に使いこなせます。例えばTool定義だけはLangChainで行い、OpenAIライブラリで呼び出す際はLangChainのconvert_to_openai_tool で対応する形式変換し、OpenAIライブラリでリクエストするといった方法も使えます。
執筆
AIソリューショングループ
後藤勇輝

