ChatGPTと自社データ活用 - Azure OpenAI Service On Your Dataの課題(前編)
はじめに
こんにちは、AITC 製品開発グループの矢作です。
Microsoft Build 2023で、Azure OpenAI Service On Your DataのPublic Preview が発表されましたね。
本機能は、OpenAIのモデルを自身(自社)のデータにノーコードで活用できる革新的な機能となっており、待ち望んだ方も多いと思います。これにより自身や自社が保有するファイルに対してChatGPTのように対話形式で問いかけて情報を得ることが可能になります。
本記事では、実際にAzure OpenAI Service On Your Dataを試してみた結果を基に、精度面で感じた課題を紹介します。
Azure OpenAI Service On Your Dataとは
Azure OpenAI Service On Your Dataは、自身や自社が所有する未公開のファイルに対してChatGPTのような対話形式で質問することができる機能です。
これまで、ChatGPTに自社データを組み込むためには こちらのサンプルコード に記載されているようなアーキテクチャを構築する必要があり、気軽に利用できるものではありませんでした。しかし、 Azure OpenAI Service On Your Dataを使うことで、GUI上のシンプルな操作だけでこれらを実現できるようになります。
使用データ
今回の検証には、AITCコラムに掲載されている記事を使用しました。
ファイルのアップロード
使用するデータをChatGPTのプレイグラウンド上にある『Add your data(preview)』タブからアップロードします。
Blob StorageやCongnitive Searchのリソースは任意のものを選択します。
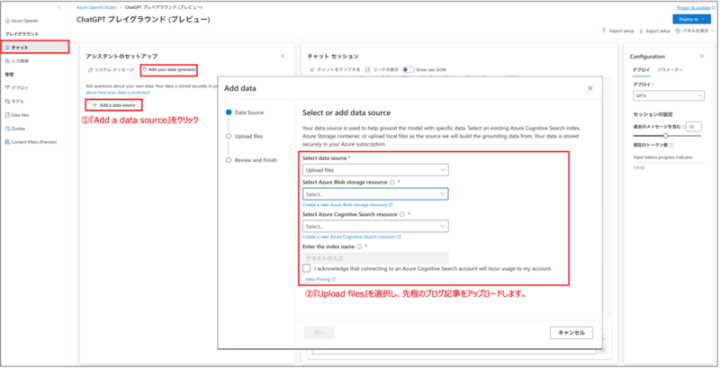
ファイルのアップロードが完了するとインデックスが登録されます。

これで準備は終了です。
実際にチャットセッションで質問を投げてみましょう。
検証
今回は、以下の二つのケースに焦点を当てて検証してみます。
- 一つの文書から回答を生成するケース
- 複数の文書から回答を生成するケース
1つ目は、ある製品の情報が一つのマニュアルにまとめられていて、そこから操作方法などを知りたい場合のユースケースを想定してます。2つ目は、業界レポートやニュース記事など複数文書の情報を要約したい場合のユースケースを想定しています。
これらのユースケースは、文書を活用する上でよく見られるシチュエーションだと思います。
複数文書から回答生成する分、2の方が難しいケースとなってます。
では、実際に検証してみましょう。
1. 一つの文書から回答を生成するケース
まずは、一つの文書から回答を生成するケースを試してみましょう。
質問:2022年度の人工知能学会の開催地を教えてください。(正解は京都)
On Your Dataの回答:JSAI2022は2022年6月14日から17日にかけて京都で開催されました。
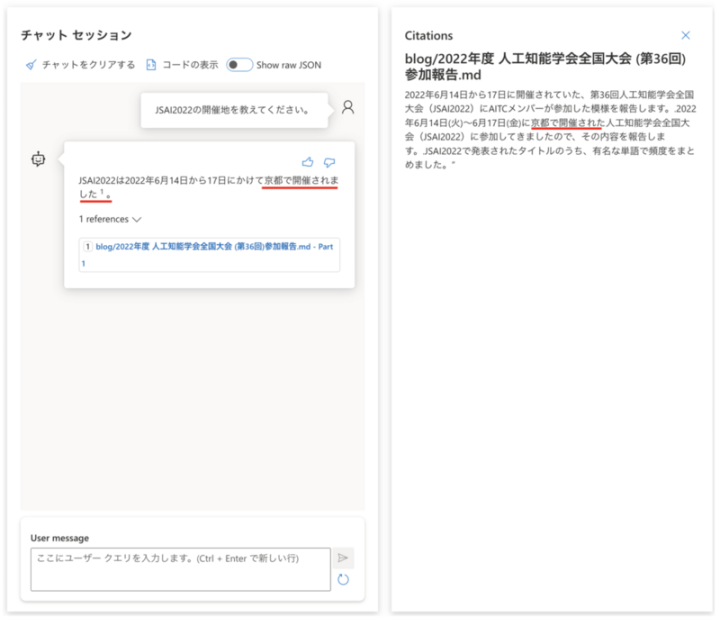
正しい回答が生成できてますね。
Citationsから回答生成に使用したデータを確認することができるため、内容の真偽もすぐに確認できるのも便利ですね。
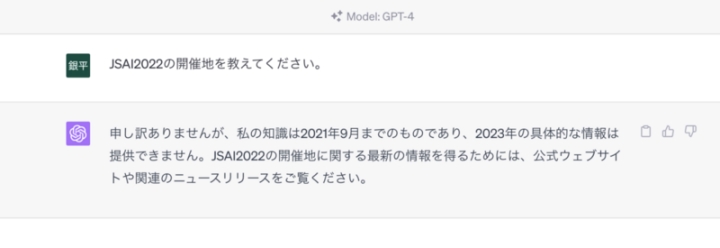
また、ChatGPTにも同じ質問をしてみました。
当たり前ですが、ChatGPTが持つ情報は2021年9月までのものであるため質問に答えることができません。つまり、先程の結果はアップロードした文書から回答生成していることがわかります。
2. 複数の文書から回答を生成するケース
次は、複数の文書から回答を生成するケースを試してみましょう。
質問:
以下の学会の開催地を教えてください。
① JSAI2022
② JSAI2023
③ NLP2023
(正解は、①京都、②熊本、③沖縄)
On Your Dataの回答:JSAI2022は京都で開催されました。JSAI2023は熊本で開催されました。しかし、NLP2023の開催地についての情報は見つかりませんでした。

回答できているのは3件中2件(NLP2023の開催場所だけ回答できない)という結果になりました。ただし、Citationsは3件全て拾えていますね。
なぜ、Citationsが拾えているにも関わらず回答できないのでしょうか?
実際にCitationsを比較してみましょう。

どうやら、質問に含まれるキーワード『JSAI2022』『JSAI2023』『NLP2023』が含まれるセンテンス(文)をCitationsとして抽出しているようです。
また、『NLP2023』の質問に対して回答できなかったのは、そのキーワードを含む文に開催地の情報が含まれていなかったからと推測できます。おそらく、トークン長を抑えるためにキーワードが含まれるセンテンスのみを抽出して回答を生成していると思われます。
これについて、さらに検証してみましょう。
以下のようにNLP2023の記事の一部を修正します。

再度インデックスを作成し、同じ質問をしてみましょう。
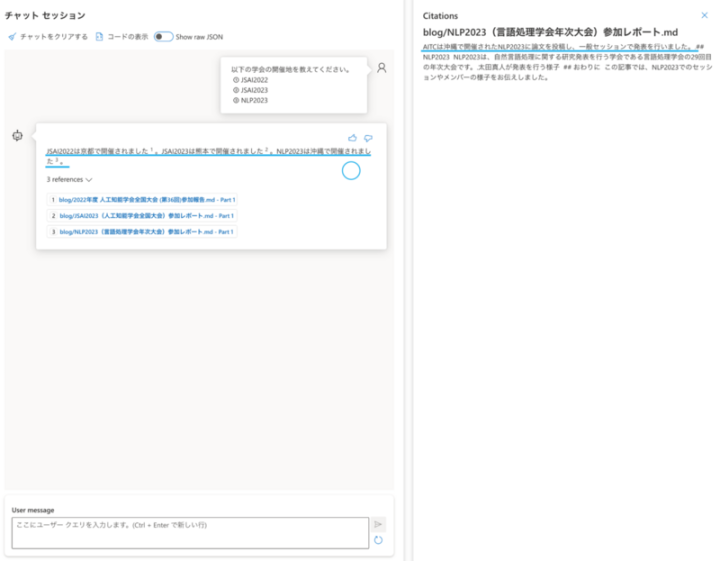
回答が生成できるようになりました。
やはり、トークン長を抑えるためにキーワードが含まれるセンテンスを抽出し、そこから回答を生成しているようです。
したがって、キーワードと回答が別の文にある場合、回答を生成できない可能性が高いです。
今回のように、キーワードと回答が同一のセンテンスに含まれるとは限らないので、この制限が実用の際に大きな不便さを生じる可能性があります。
最後に
「記事を最後までお読みいただき、ありがとうございます。
今回は、Microsoft Build 2023で発表されたAzure OpenAI Serviceの新機能、「On Your Data」について紹介しました。
この機能は、ChatGPTと自社データをノーコードで組み合わせることが可能なため、パッと検証してみるには非常に便利な機能である一方、精度面に課題があることが明らかになりました。
また、AITCでは『Know Narrator』というChatGPTソリューションを開発しています。
その一つの『Know Narrator Search』は、Azure OpenAI Service On Your Data と同様に、社内文書を活用するためのソリューションです。
次回の後編では、『Know Narrator Search』とAzure OpenAI Service On Your Dataの両者を比較します。

執筆
AITC AI製品開発グループ
矢作 銀平

